Application - Graph Prolongation Convolutional Networks
Building off of the multiscale neural network training ideas introduced in the previous chapter, we here apply a similar idea to train a Graph Convolutional Network, a model which excels at handling unstructured data. The problem we apply our model to is the prediction of energetic behavior of a rigid protein structure called a microtubule.
Convolution and Graph Convolution
Recent successes of deep learning have demonstrated that the inductive bias of Convolutional Neural Networks (CNNs) makes them extremely efficient for analyzing data with an inherent grid structure, such as images or video. In particular, many applications use these models to make per-node (per-pixel) predictions over grid graphs: examples include image segmentation, optical flow prediction, anticipating motion of objects in a scene, and facial detection/identification. Further work applies these methods to emulate physical models, by discretizing the input domain. Computational Fluid Dynamics and other scientific tasks featuring PDEs or ODEs on a domain discretized by a rectangular lattice have seen recent breakthroughs applying machine learning models, like CNNs to handle data which is structured this way. These models learn a set of local filters whose size is much smaller than the size of the domain - these filters may then be applied simultaneously across the entire domain, leveraging the fact that at a given scale the local behavior of the neighborhood around a pixel (voxel) is likely to be similar at all grid points.
Graph Convolutional Networks (GCNs) are a natural extension of the above idea of image ‘filters’ to arbitrary graphs rather than D grids, which may be more suitable in some scientific contexts. Intuitively, GCNs replace the image filtering operation of CNNs with repeated passes of: 1) aggregation of information between nodes according to some structure matrix 2) nonlinear processing of data at each node according to some rule (most commonly a flat neural network which takes as separate input(s) the current vector at each node). We refer the reader to a recent survey by Bacciu et al (Bacciu et al. 2019) for a more complete exploration of the taxonomy graph neural networks.
Microtubules
As an example of a dataset whose underlying graph is not a grid, we consider a coarse-grained simulation of a microtubule. Microtubules (MTs) are self-assembling nanostructures, ubiquitous in living cells, that along with actin filaments comprise a major portion of the dynamic cytoskeleton governing cell shape and mechanics. Whole-MT biomechanical models would be a useful tool for modeling cytoskeletal dynamics at the cellular scale. MTs play important structural roles during cell division, cell growth, and separation of chromosomes (in eukaryotic cells) (Chakrabortty et al. 2018). Microtubules are comprised of a lattice structure of two conformations ( and ) of tubulin. Free-floating tubulin monomers associate energetically into dimer subunits, which then associate head-to-tail to form long chain-like complexes called protofilaments. Protofilaments associate side-to side in a sheet; at some critical number of protofilaments (which varies between species and cell type) the sheet wraps closed to form a repeating helical lattice with a seam. See (Pampaloni and Florin 2008), Page 303, Figure 1. Key properties of microtubules are:
Dynamic instability: microtubules grow from one end by attracting free-floating tubulin monomers (VanBuren, Cassimeris, and Odde 2005). Microtubules can spontaneously enter a “catastrophe” phase, in which they rapidly unravel, but can also “rescue” themselves from the catastrophe state and resume growth (Gardner, Zanic, and Howard 2013; Shaw, Kamyar, and Ehrhardt 2003).
Interactions: Microtubules interact with one another: they can dynamically avoid one another during the growth phase, or collide and bundle up, or collide and enter catastrophe (Tindemans et al. 2014). The exact mechanism governing these interactions is an area of current research.
Structural strength: microtubules are very stiff, with a Young’s Modulus estimated at 1GPa for some cases (Pampaloni and Florin 2008). This stiffness is thought to play a role in reinforcing cell walls (Kis et al. 2002).
In this work we introduce a model which learns to reproduce the dynamics of a graph signal (defined as an association of each node in the network with a vector of discrete or real-valued labels) at multiple scales of graph resolution. We apply this model framework to predict the potential energy of each tubulin monomer in a simplified mechanochemical simulation of a microtubule. This trial dataset illustrates the efficiency of our proposed type of graph convolutional network and is a solid proof-of-concept for applying this model to more biologically accurate microtubule models in the future. In the next section, we discuss the wide variety of microtubule simulations which have been previously studied.
Simulation of MTs and Prior Work
Non-continuum, non-event-based simulation of large molecules is typically done by representing some molecular subunit as a particle/rigid body, and then defining rules for how these subunits interact energetically. Molecular Dynamics (MD) simulation is an expansive area of study and a detailed overview is beyond the scope of this paper. Instead, we describe in general terms some basic ideas relevant to the numerical simulation detailed in Section 7.4.1. MD simulations proceed from initial conditions by computing the forces acting on each particle (according to the potential energy interactions and any external forces, as required), determining their instantaneous velocities and acceleration accordingly, and then moving each particle by the distance it would move (given its velocity) for some small timestep. Many variations of this basic idea exist. The software we use for our MD simulations, LAMMPS (Plimpton 1993) allows for many different types of update step: we use Verlet integration (updating particle position according to the central difference approximation of acceleration (Verlet 1967)) and Langevin dynamics (modeling the behavior of a viscous surrounding solvent implicitly (Schneider and Stoll 1978)). We also elect to use the microcanonical ensemble (NVE) - meaning that the update steps of the system maintain the total number of particles, the volume of the system, and the total energy (kinetic + potential).Simulation of microtubules is an area of active research, and there are many fundamental questions yet to be answered. A brief review of previous MT simulation studies (Stewman and Ma 2018; Gardner et al. 2008; Molodtsov et al. 2005; VanBuren, Cassimeris, and Odde 2005; Wang and Nogales 2005; Margolin et al. 2012) finds a wide variety of different simulation techniques and assumptions. For this reason, we choose a simple model which is in a qualitative sense the “lowest common denominator” of many of these models. Our microtubule simulation is a fixed structure of tubulin with energy terms defined only for tubulin-tubulin associations (consisting of angle and edge length constraints between monomers). We simulated the behavior of this structure under bending load in the MD software package LAMMPS (Plimpton 1993) using Verlet integration (Verlet 1967) and an implicit surrounding solvent (Schneider and Stoll 1978). For more details of our simulation, see Section 7.4.1 and the source code, available in the Supplementary Material accompanying this paper. Independent of implementation details, a common component of many experiments in computational molecular dynamics is the prediction of the potential energy associated with a particular conformation of some molecular structure. Understanding the energetic behavior of a complex molecule yields insights into its macro-scale behavior: for instance, the problem of protein folding can be understood as seeking a lower-energy configuration. Each timestep of our simulator produces a vector consisting of each monomer’s contribution to the total potential energy of the structure at that timestep, as detailed in Section 7.4.1. This vector is the target output we want our machine learning model to predict. In this work, we apply graph convolutional networks, trained via a method we introduce, to predict these energy values for a section of microtubule.
Model Architecture and Mathematical Details
Model Description
Many approaches to scientific problems benefit from the use of multiscale analysis: separating the behavior at hand into multiple scale lengths and analyzing each separately. We expect in general to have different phenomena at different scales, therefore necessitating varying treatments; a typical example would be a hybrid computational mechanics solver which uses both a continuum model at the largest spatial scale, but models spatially smaller interactions with an all-atom simulation (Stüben 2001; Wesseling and Oosterlee 2001). Even when phenomena are the same across multiple spatial scales (i.e. solving the Navier-Stokes equations on irregular domains (Raw 1996)) we expect to see acceleration of simulations when we use a multiscale architecture, as in the case of Multigrid solvers for iterative systems. These methods work on the premise that it if the wavelength of an error is large in comparison to the scale length considered by a solver, it may take many iterative steps at that scale to resolve the error. It is therefore advantageous to resolve errors at a scale similar to their characteristic wavelength, which is accomplished by building a hierarchy of solvers which each address error at a particular scale length. The exact method for reduction in error (a “smoothing” step) is problem dependent; however, strategies for stepping between spatial scales have been invented, with good theoretical guarantees for accelerated error reduction of the entire system.
It is here necessary to note that the scheduling dictates which scale of error is reduced at a given step in the algorithm. In multigrid methods, the actual fine-to-coarse mapping (or vice versa) is given by multiplying the current solution by either a restriction or prolongation matrix, respectively. Typically these matrices are constrained, for example to be norm-preserving. This is similar in both motivation and practice to the matrix multiplication we use in our model architecture, detailed below and in Section 7.3.4.
Multiscale architectures are also a staple of machine learning methods. Convolutional Neural Networks, as described in section 7.1, are an example of such a system: features are propagated through the network so that the nodes in the final layer are aggregating information from a wide visual area. Motivated by both CNNs and the multiscale method literature, we develop a model which uses a multiscale architecture to learn molecular dynamics at multiple spatial scales. Input is coarsened to each of these scales by applying an optimized linear projection (for details of this optimization, see Section 7.4.2). At each scale, a graph convolutional network processes that scale’s information, analogous to the lateral connections in U-Net (Ronneberger, Fischer, and Brox 2015). Again analogously to the “upscaling” connection in U-Net, the output of these GCNs is upsampled using the inverse of the same optimized linear projection used in the prior downsampling step. These outputs are all summed to produce a final model prediction at the finest scale. In the rest of this section, we first provide some general mathematical background (Section 7.3.2), formally define Graph Convolution (Section 7.3.3), and finally use these definitions to formally specify our model architecture in (Section 7.3.4)
Mathematical Background
Definitions:
For all basic terms (graph, edge, vertex, degree) we use standard definitions. We use the notation to represent the sequence of indexed by the integers . When is a matrix, we will write to denote the entry in the th row, th column.
Graph Laplacian: The graph Laplacian is the matrix given by where is the adjacency matrix of , and is an appropriately sized vector of 1s. The graph Laplacian is given by some authors as the opposite sign.
Linear Graph Diffusion Distance (GDD): Given two graphs and , with the Linear Graph Diffusion Distance is given by: where represents some set of constraints on , is a scalar with , and represents the Frobenius norm. We take to be orthogonality: . Note that since in general is a rectangular matrix, it may not be the case that . Unless stated otherwise all matrices detailed in this work were calculated with , using the procedure laid out in the following section, in which we briefly detail an algorithm for efficiently computing the distance in the case where is allowed to vary. The efficiency of this algorithm is necessary to enable the computation of the LGDD between very large graphs, as discussed in Section 7.6.3.
Prolongation matrix: we use the term “prolongation matrix” to refer to a matrix which is the optimum of the minimization given in the definition of the LGDD.
Graph Convolutional Layer Definition
We follow the GCN formulation given by Kipf and Welling (Kipf and Welling 2016). Assuming an input tensor of dimensions (where is the number of nodes in the graph and is the dimension of the label at each node), we inductively define the layerwise update rules for a graph convolutional network $\textsc{gcn}\left(Z_i, X, {\left\{\theta^{(i)}_{l} \right\}}_{l=1}^{m}\right)$ as: where is the activation function of the th layer.
Graph Prolongation Convolutional Networks
The model we propose is an ensemble of GCNs at multiple scales, with optimized projection matrices performing the mapping in between scales (i.e. between ensemble members). More formally, Let represent a sequence of graphs with , and let be their structure matrices (for some chosen method of calculating the structure matrix given the graph). In all experiments in this paper, we take , the graph Laplacian, as previously defined.1 In an ensemble of Graph Convolutional Networks, let represent the parameters (filter matrix and bias vector) in layer of the th network.
When , let be an optimal (in either the sense of Graph Diffusion Distance, or in the sense we detail in section 7.5.5) prolongation matrix from to , i.e. Then, for , let be shorthand for the matrix product . For example, .
Our multiscale ensemble model is then constructed as:
$$\begin{aligned}
&\textbf{GPCN}\left(
\left\{Z_{i} \right\}_{i=1}^{k},
X,
\left\{ \left\{\theta^{(i)}_l \right\}_{l=1}^{m_i} \right\}_{i=1}^{k},
\left\{ P_{i,i+1} \right\}_{i=1}^{k-1}
\right) \nonumber\\
&\null\quad = \textsc{gcn}\left(Z_1, X, \left\{\theta^{(1)}_l \right\}_{l=1}^{m_1} \right)\nonumber\\
&\null\quad\quad+ \sum_{i=2}^{k} P_{1i} \textsc{gcn}\left(
Z_i,
P_{1i}^T X,
\left\{\theta^{(i)}_l \right\}_{l=1}^{m_i}
\right) \label{eqn:gpcn_forward_rule}
\end{aligned}$$ This model architecture is illustrated in Figure [fig:gcn_schematic]. When the matrices are constant/fixed, we will refer to this model as a GPCN, for Graph Prolongation-Convolutional Network. However, we find in our experiments in Section 7.5.5 that validation error is further reduced when the operators are tuned during the same gradient update step which updates the filter weights, which we refer to as an “adaptive” GPCN or A-GPCN. We explain our method for choosing and optimizing matrices in Section 7.5.5.
![Top: Schematic of GPCN model. Data matrix X is fed into the model and repeatedly coarsened using optimized projection matrices P_{ik}, illustrated by purple arrows. These coarsened data matrices are separately fed into GCN models, producing predictions at each scale. Each blue arrow represents an upsample-and-add operation, where the upsampling is performed with the transpose of the P_{ik}. The final output of the ensemble is the projected sum of the outputs of each component GCN.Middle and bottom: mathematical details of upsampling and downsampling steps from top diagram. See Equation [eqn:gpcn_forward_rule] for details.](../media/file41.png "fig:")
![Top: Schematic of GPCN model. Data matrix X is fed into the model and repeatedly coarsened using optimized projection matrices P_{ik}, illustrated by purple arrows. These coarsened data matrices are separately fed into GCN models, producing predictions at each scale. Each blue arrow represents an upsample-and-add operation, where the upsampling is performed with the transpose of the P_{ik}. The final output of the ensemble is the projected sum of the outputs of each component GCN.Middle and bottom: mathematical details of upsampling and downsampling steps from top diagram. See Equation [eqn:gpcn_forward_rule] for details.](../media/file42.png "fig:")
![Top: Schematic of GPCN model. Data matrix X is fed into the model and repeatedly coarsened using optimized projection matrices P_{ik}, illustrated by purple arrows. These coarsened data matrices are separately fed into GCN models, producing predictions at each scale. Each blue arrow represents an upsample-and-add operation, where the upsampling is performed with the transpose of the P_{ik}. The final output of the ensemble is the projected sum of the outputs of each component GCN.Middle and bottom: mathematical details of upsampling and downsampling steps from top diagram. See Equation [eqn:gpcn_forward_rule] for details.](../media/file43.png "fig:")
[fig:gcn_schematic]
Dataset Generation and Reduced Model Construction
In this section we describe some of the ancillary numerical results needed to reproduce and understand our main machine learning results in Section 7.5.
Dataset
In this Section we detail the process for generating the simulated microtubule data for comparison of our model with other GCN ensemble models. Our microtubule structure has 13 protofilaments (each 48 tubulin monomers long). As in a biological microtubule, each tubulin monomer is offset (along the axis parallel to the protofilaments) from its neighbors in adjacent protofilaments, resulting in a helical structrure with a pitch of 3 tubulin units. We refer to this pitch as the “offset” in Section 7.4.3. Each monomer subunit (624 total) is represented as a point mass of 50 Dalton ( ng). The diameter of the whole structure is 26 nm, and the length is nm. The model itself was constructed using Moltemplate (Jewett, Zhuang, and Shea 2013), a tool for constructing large regular molecules to be used in LAMMPS simulations. Our Moltemplate structure files were organized hierarchically, with: tubulin monomers arranged into - dimer pairs; which were then arranged into rings of thirteen dimers; which were then stacked to create a molecule 48 dimers long. Note that this organization has no effect on the final LAMMPS simulation: we report it here for reproducibility, as well as providing the template files in the supplementary material accompanying this paper.
For this model, we define energetic interactions for angles and associations only. No steric or dihedral interactions were used: for dihedrals, this was because the lattice structure of the tube meant any set of four molecules contributed to multiple, contradictory dihedral interactions.2 Interaction energy of an association was calculated using the “harmonic” bond style in LAMMPS, i.e. where is the resting length and is the strength of that interaction ( varies according to bond type). The energy of an angle was similarly calculated using the “harmonic” angle style, i.e. where is the resting angle and is again the interaction strength, and again depends on the angle type of 3. The resting lengths and angles for all energetic interactions were calculated using the resting geometry of our microtubule graph : a LAMMPS script was used to print the value of every angle interaction in the model, and these were collected and grouped based on value (all angles, all angles, etc). Each strength parameter was varied over the values in , producing parameter combinations. Langevin dynamics were used, but with small temperature, to ensure stability and emphasize mechanical interactions. See Table [tab:ener_inter] and Figure [fig:mt_labelled] for details on each strength parameter. See Figure [fig:param_vary] for an illustration of varying resting positions and final energies as a result of varying these interaction parameters.
GNU Parallel (Tange 2011) was used to run a simulation for each combination of interaction parameters, using the particle dynamics simulation engine LAMMPS. In each simulation, we clamp the first two rings of tubulin monomers (nodes 1-26) in place, and apply force (in the negative direction) to the final two rings of monomers (nodes 599-624). This force starts at 0 and ramps up during the first 128000 timesteps (one step ns) to its maximum value of N. Once maximum force is reached, the simulation runs for 256000 additional timesteps, which in our experience was long enough for all particles to come to rest. See Figure [fig:bend_mt] for an illustration (visualized with Ovito (Stukowski, n.d.)) of the potential energy per-particle at the final frame of a typical simulation run. Every timesteps, we save the following for every particle: the position ; components of velocity ; components of force ; and the potential energy of the particle . The dataset is then a concatenation of the 12 saved frames from every simulation run, comprising all combinations of input parameter values, where for each frame we have:
, the input graph signal, a matrix holding the position and velocity of each particle, as well as values of the four interaction coefficients; and
, the output graph signal, a matrix holding the potential energy calculated for each particle.
We note here that none of the inputs to the model encode information about any of the statistics of the system as a whole (for example, the total energy, the temperature or density of the surrounding solvent, etc). This was not necessary in our example simulations because these factors did not vary in our experiment. A more detailed data input would likely be necessary for our model to be implemented in a more complicated simulation scenario that tuned any of these system quantities between runs.
During training, after a training/validation split, we normalize the data by taking the mean and standard deviation of the input and output tensors along their first axis. Each data tensor is then reduced by the mean and divided by the standard deviation so that all inputs to the network have zero mean and unit standard deviation. We normalize using the training data only.
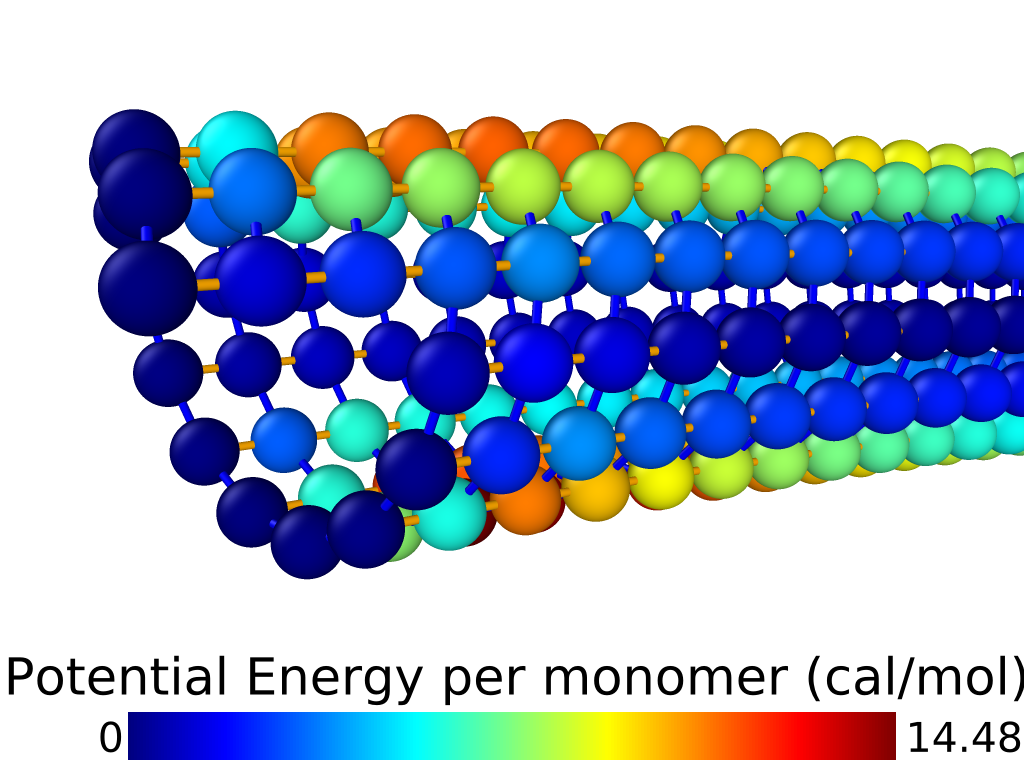
[fig:bend_mt]
![Microtubule model structure. Red spheres represent \alpha-tubulin; purple spheres represent \beta-tubulin. Highlighted atoms at center are labelled to show example energetic interactions: each type of interaction indicated in Table [tab:ener_inter] (using the particle labels in this image) is applied everywhere in the model where that arrangement of particle and association types occurs in that position.](../media/file45.png)
[fig:mt_labelled]
![Changes in stiffness of microtubule model under constant load, as parameters controlling interaction strength are varied. We see qualitiative differences in behavior as spring constants are adjusted between 0.1 and 1.9. The left and right images show the final timestep of simulations where all spring constants were set to the minimum and maximum strength, respectively. Particles (tubulin monomers) are colored according to their contribution to total potential energy of the configuration, identically to Figure [fig:bend_mt]. All pictures show the microtubule at rest e.g. at the end of the simulation run using that parameter set.](../media/file46.png "fig:")
![Changes in stiffness of microtubule model under constant load, as parameters controlling interaction strength are varied. We see qualitiative differences in behavior as spring constants are adjusted between 0.1 and 1.9. The left and right images show the final timestep of simulations where all spring constants were set to the minimum and maximum strength, respectively. Particles (tubulin monomers) are colored according to their contribution to total potential energy of the configuration, identically to Figure [fig:bend_mt]. All pictures show the microtubule at rest e.g. at the end of the simulation run using that parameter set.](../media/file47.png "fig:")
[fig:param_vary]
c
Association interactions
| Description | Examples | Resting Length | Strength Param. |
| Lateral association inside lattice | (1,3),(2,4) | 5.15639nm | LatAssoc |
| Lateral association across seam | (5,8),(6,9) | 5.15639nm | LatAssoc |
| Longitudinal association | (1,2),(3,4) | 5.0nm | LongAssoc |
angle interactions
| Description | Examples | Resting Angle | Strength Param. |
| Pitch angle inside lattice | (1,3,5),(2,4,6) | 153.023 | LatAngle |
| Longitudinal angle | (5,6,7),(8,9,10) | 180 | LongAngle |
| Lattice cell acute angle | (3,4,6),(3,5,6),(5,8,9),(6,9,10) | 77.0694 | QuadAngles |
| Lattice cell obtuse angle | (4,3,5),(4,6,5),(6,5,8),(6,9,8) | 102.931 | QuadAngles |
[tab:ener_inter]
Efficient Calculation of Graph Diffusion Distance
The joint optimization given in the definition of Linear Graph Diffusion Distance (Equation [eqn:GDD]) is a nested optimization problem. If we set then each evaluation of requires a full optimization of the matrix subject to constraints . When and are Graph Laplacians, is continuous, but with discontinuous derivative, and has many local minima (see Figure [fig:lin_dist_ex]). As a result, the naive approach of optimizing using a univariate optimization method like Golden Section Search is inefficient. In this section we briefly describe a procedure for performing this joint optimization more efficiently. For a discussion of variants of the LGDD, as well as the theoretical justification of this algorithm, see (C. B. Scott and Mjolsness 2019).
First, we note that by making the constraints on more restrictive, we upper-bound the original distance: In our case, represents orthogonality. As a restriction of our constraints we specify that must be related to a subpermutation matrix (an orthogonal matrix having only 0 and 1 entries) $\Tilde{P}$ as follows: $P = U_2 \Tilde{P} U_1^T$, where the are the fixed matrices which diagonalize : . Then,
$$\begin{aligned} D(G_1, G_2) &\leq \inf_{\substack{P|\mathcal{S}(P)\\\alpha > 0}} {\left| \left| \frac{1}{\alpha} P L(G_1) - \alpha L(G_2) P \right| \right|}_F \nonumber \\ &= \inf_{\substack{\Tilde{P}|\text{subperm}(\Tilde{P})\\\alpha > 0}} {\left| \left| \frac{1}{\alpha} U_2 \Tilde{P} U_1^T U_1 \Lambda_1 U_1^T \right. \right.} \nonumber \\ & \null \qquad \qquad \qquad {\left. \left. - \alpha U_2 \Lambda_2 U_2^T U_2 \Tilde{P} U_1^T \right| \right|}_F \nonumber \\ &= \inf_{\substack{\Tilde{P}|\text{subperm}(\Tilde{P})\\\alpha > 0}} {\left| \left| \frac{1}{\alpha} U_2 \Tilde{P} \Lambda_1 U_1^T - \alpha U_2 \Lambda_2 \Tilde{P} U_1^T \right| \right|}_F \nonumber \\ &= \inf_{\substack{\Tilde{P}|\text{subperm}(\Tilde{P})\\\alpha > 0}} {\left| \left| U_2 \left( \frac{1}{\alpha} \Tilde{P} \Lambda_1 - \alpha \Lambda_2 \Tilde{P} \right) U_1^T \right| \right|}_F. \nonumber \intertext{Because the $U_i$ are rotation matrices (under which the Frobenius norm is invariant), this further simplifies to} D(G_1, G_2) &\leq \inf_{\substack{\Tilde{P}|\text{subperm}(\Tilde{P})\\\alpha > 0}} {\left| \left| \frac{1}{\alpha} \Tilde{P} \Lambda_1 - \alpha \Lambda_2 \Tilde{P} \right| \right|}_F. \nonumber \end{aligned}$$ Furthermore, because the are diagonal, this optimization is equivalent to a Rectangular Linear Assignment Problem (RLAP) (Bijsterbosch and Volgenant 2010), between the diagonal entries and of and , respectively, with the -dependent cost of an assignment given by: .
RLAPs are extensively studied. We use the general LAP solving package lapsolver (Heindl 2018) to comute $\Tilde{P}$. In practice (and indeed in this paper) we set often set , in which case the solution $\Tilde{P}$ of the RLAP only acts as a preconditioner for the orthogonally-constrained optimization over . More generally, when alpha is allowed to vary (and therefore many RLAPs must be solved), a further speedup is attained by re-using partial RLAP solutions from previously-tested values of to find the optimal assignment at . We detail how this may be done in out recent work (C. B. Scott and Mjolsness 2019).
For the matrices used in the experiments in this work, we set and used lapsolver to find an optimal assignment $\Tilde{P}$. We then initialized an orthogonally-constrained optimization of [eqn:GDD] with $P = U_2 \Tilde{P} U_1^T$. This constrained optimization was performed using Pymanopt (Townsend, Koep, and Weichwald 2016).
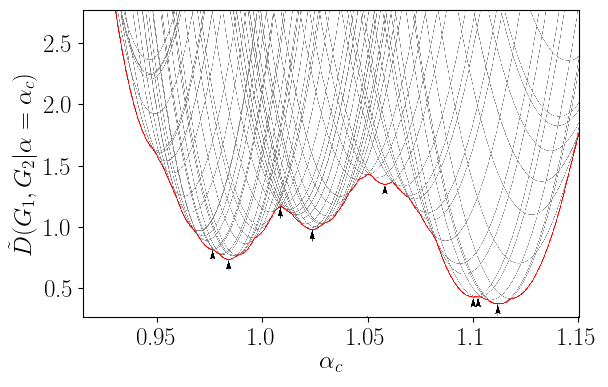
[fig:lin_dist_ex]
Graph Coarsening

[fig:mt_dist_table]
[fig:my_label]
In this Section we outline a procedure for determining the coarsened structure matrices to use in the hierarchy of GCN models comprising a GPCN. We use our microtubule graph as an example. In this case, we have two a-priori guidelines for producing the reduced-order graphs: 1) the reduced models should still be a tube and 2) it makes sense from a biological point of view to coarsen by combining the - pairs into single subunits. Given these restrictions, we can explore the space of coarsened graphs and find the coarse graph which is nearest to our original graph (under the GDD).
Our microtubule model is a tube of length 48 units, 13 units per complete “turn”, and with the seam offset by three units. We generalize this notion as follows: Let be the offset, and be the number of monomers in one turn of the tube, and the number of turns of a tube graph . The graph used in our simulation is thus . We pick the medium scale model to be , as this is the result of combining each pair of tubulin monomer units in the fine scale, into one tubulin dimer unit in the medium scale. We pick the coarsest graph by searching over possible offset tube graphs. Namely, we vary and , and compute the optimal and its associated distance . Figure [fig:mt_dist_table] shows the distance between and various other tube graphs as parameters and are varied. The nearest to is that with and . Note that Figure [fig:mt_dist_table] has two columns for each value of : these represent the coarse edges along the seam having weight (relative to the other edges) 1 (marked with an ) or having weight 2 (no ). This is motivated by the fact that our initial condensing of each dimer pair condensed pairs of seam edges into single edges.
Machine Learning Experiments
Experimental Procedure
This section contains several experiments comparing our model, and its variants, to other types of Graph Convolutional Networks. All models were trained using ADAM with default hyperparameters, in TensorFlow (Abadi et al. 2016). Random seeds for Python, TensorFlow, Numpy, and Scipy were all initialized to the same value for each training run, to ensure that the train/validation split is the same across all experiments, and the batches of drawn data are the same. See supplementary material for version numbers of all software packages used. Training batch size was set to 8, all GCN layers have ReLU activation, and all dense layers have sigmoidal activation with the exception of the output layer of each network (which is linear). All modes were trained for 1000 epochs of 20 batches each. The time per batch of each model is listed in Table [tab:wallclock].
Since hardware implementations may differ, we estimate the computational cost in Floating Point OPerations (FLOPs) of each operation in our models. The cost of a graph convolutional layer with structure matrix , input data , and filter matrix is estimated as: , where is the number of nonzero entries of . This is calculated as the sum of the costs of the two matrix multiplications and , with the latter assumed to be implemented as sparse matrix multiplication and therefore requiring operations. For implementation reasons, our GCN layers (across all models) do not use sparse multiplication; if support for arbitrary-dimensional sparse tensor outer products is included in TensorFlow in the future, we would expect the wall-clock times in Table [tab:wallclock] to decrease. The cost of a dense layer (with input data , and filter matrix ) applied to every node separately is estimated as: . The cost of taking the dot product between a matrix and a matrix (for example, the restriction/prolongation by ) is estimated as .
For GPCN models, matrices were calculated using Pymanopt (Townsend, Koep, and Weichwald 2016) to optimize Equation [eqn:GDD] subject to orthogonality constraints. The same were used to initialize the (variable) matrices of A-GPCN models.
Evaluation of GPCN Variants
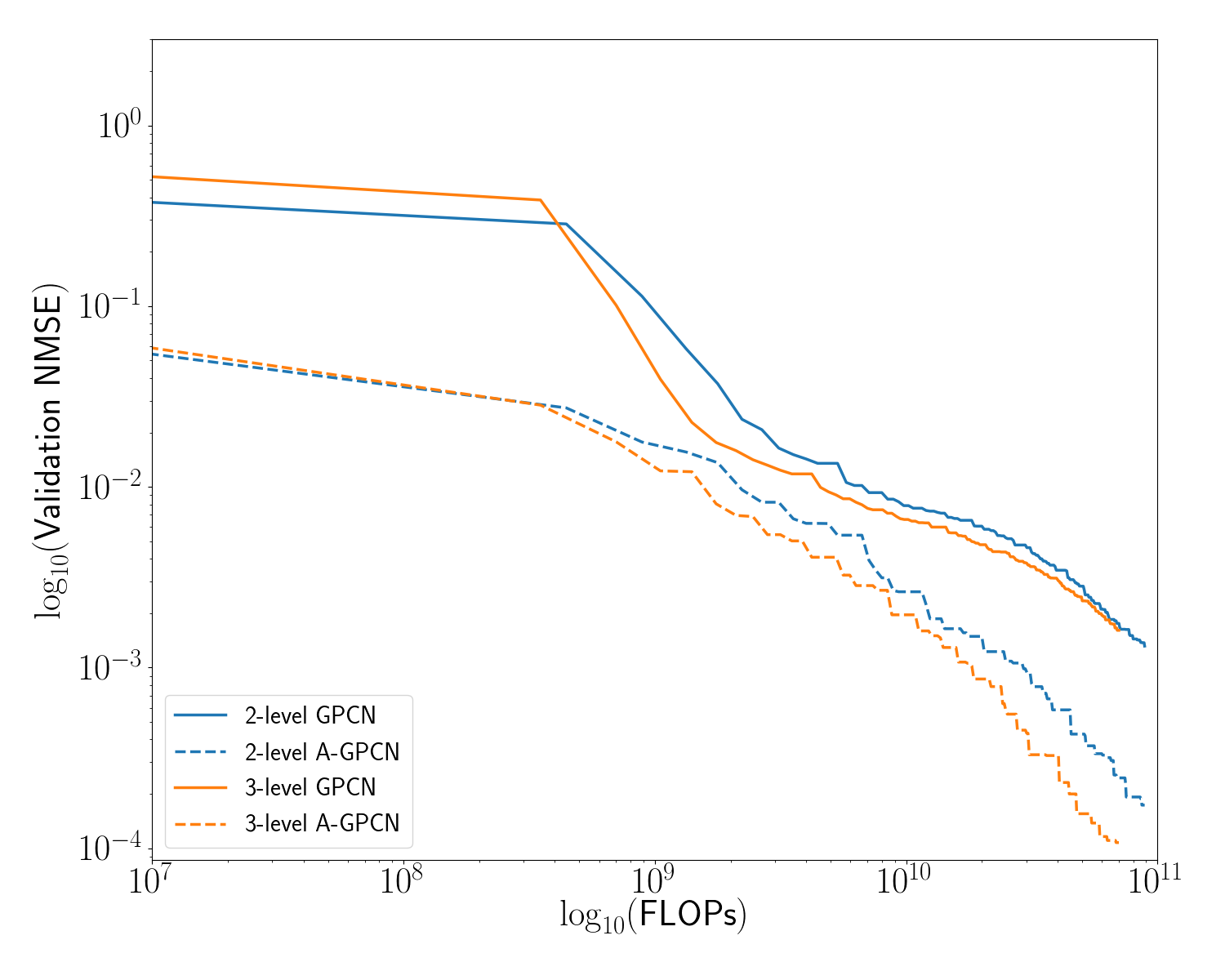
[fig:gpcn_variants]
Our proposed model uses a hierarchy of graph convolutional networks to predict energy of a molecule at several spatial scales. The computational cost of a graph convolutional layer is approximately quadratic in the number of nodes in the underlying graph. We would therefore expect to see efficiency gains when some number of graph convolution layers are operating on a reduced graph. In this subsection we present numerical experiments showing that this is indeed the case: the accuracy gained (per unit of computational expenditure) is higher for deeper hierarchies. Additionally, the adaptive model(s) universally outperform their non-adaptive counterparts.
We compare the following versions of our model:
a two-level GPCN with static -matrices;
a three-level GPCN with static -matrices;
both of the above, but with matrices allowed to vary during training (adjusted with the same backpropagation signals which are used to modify the convolution weights).
Figure [fig:gpcn_variants] and Table [tab:err_comparison] summarize these results.
Evaluation of Training Schedules
In contrast to the prior section, where we use the same training strategy and evaluate the efficiency of different variants of our model, in this section we fix the model architecture and evaluate the effect of different training schedules. Specifically, we compare the computational cost of training the entire GPCN at once, versus training the different ‘resolutions’ (meaning the different GCNs in the hierarchy) of the network according to a more complicated training schedule. This approach is motivated by recent work in coarse-to-fine training of both flat and convolutional neural networks (C. Scott and Mjolsness 2019; Zhao et al. 2019; Haber et al. 2018; Dou and Wu 2015; Ke, Maire, and Yu 2017), as well as the extensive literature on Algebraic MultiGrid (AMG) methods (Vaněk, Mandel, and Brezina 1996).
AMG solvers for differential equations on a mesh (which arises as the discretization of some volume to be simulated) proceed by performing numerical “smoothing steps” at multiple resolutions of discretization. The intuition behind this approach is that modes of error should be smooth at a spatial scale which is equivalent to their wavelength, i.e. the solver shouldn’t spend many cycles resolving long-wavelength errors at the finest scale, since they can be resolved more efficiently at the coarse scale. Given a solver and a hierarchy of discretizations, the AMG literature defines several types of training procedures or “cycle” types (F-cycle, V-cycle, W-cycle). These cycles can be understood as being specified by a recursion parameter , which controls how many times the smoothing or training algorithm visits all of the coarser levels of the hierarchy in between smoothing steps at a given scale. For example, when the algorithm proceeds from fine to coarse and back again, performing one smoothing step at each resolution - a ‘V’ cycle.
We investigate the efficiency of training 3-level GPCN and A-GPCN (as described in Section 7.5.2), using multigrid-like training schedules with , as well as “coarse-to-fine” training: training the coarse model to convergence, then training the coarse and intermediate models together (until convergence), then finally training all three models at once. Error was calculated at the fine-scale. For coarse-to-fine training convergence was defined to have occurred once 10 epochs had passed without improvement of the validation error.
Our experiments (see Figure [fig:gpcn_schedule]) show that these training schedules do result in a slight increase in efficiency of the GPCN model, especially during the early phase of training. The increase is especially pronounced for the schedules with and . Furthermore, these multigrid training schedules produce models which are more accurate than the GPCN and A-GPCN models trained in the default manner. As a final note, previous work (C. Scott and Mjolsness 2019) has shown that these types of multiscale neural network architectures, with this type of multigrid training schedule may also be more efficient in a “statistical” sense - that is, require much less data to find an equivalent or better local minimum of error. A third type of efficiency results from the fact that once trained, querying the machine learning model is faster than running an entire simulation. This means that the cost of generating the initial dataset and training the model is amortized over the time gained by using the machine learning model as an approximator. We would expect our model to also perform well under both of these latter measures of efficiency - one run of our fine-scale simulation took approximately 20 minutes, whereas querying the trained GPCN takes tenths of milliseconds. However, quantifying this possibility further is beyond the scope of this paper.


[fig:gpcn_schedule]
Comparison with DiffPool
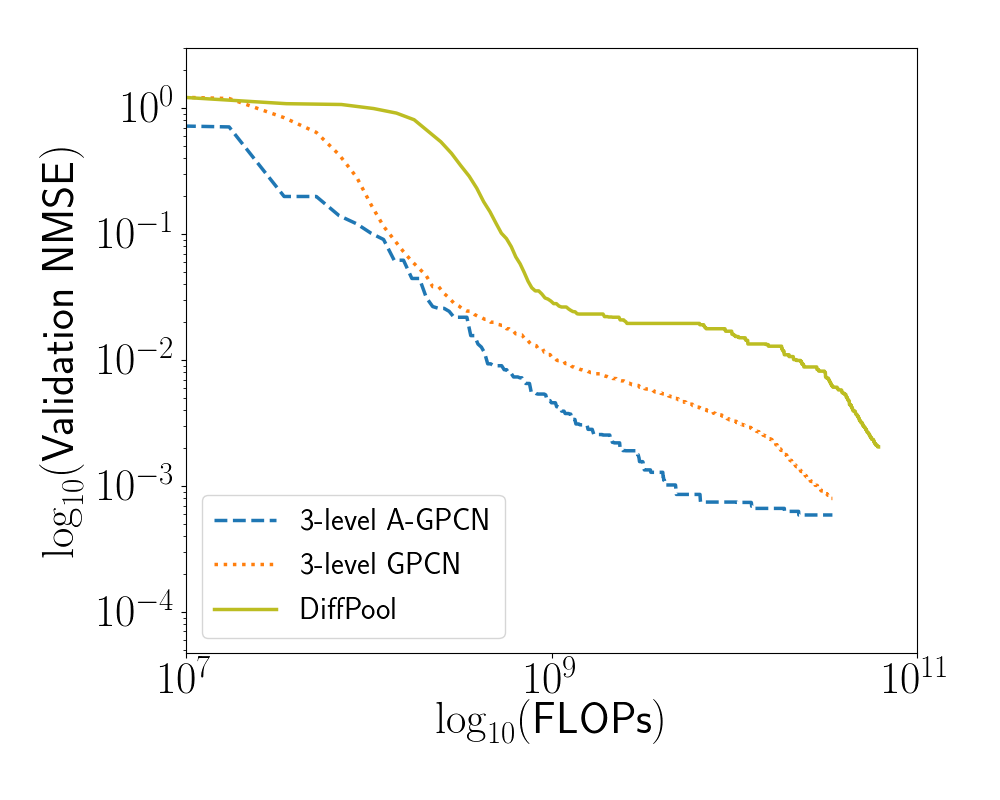
[fig:diff_comp]
Graph coarsening procedures are in general not differentiable. DiffPool (Ying et al. 2018) aims to address this by constructing an auxiliary GCN, whose output is a pooling matrix. Formally: Suppose that at layer of a GCN we have a structure matrix and a data matrix . In addition to GCN layers as described in Section 7.3, Ying et. al define a pooling operation at layer as: $$\begin{aligned} S^{(l)} &= \sigma \left( \textsc{gcn}_\text{pool}\left(Z^{(l)}, X^{(l)}, {\left\{\theta^{(i)}_1 \right\}}_{l=1}^{m}\right) \right) \end{aligned}$$ where $\textsc{gcn}_\text{pool}$ is an auxillary GCN with its own set of parameters , and is the softmax function. The output of $\textsc{gcn}_\text{pool}$ is a matrix, each row of which is softmaxed to produce an affinity matrix whose rows each sum to 1, representing each fine-scale node being connected to one unit’s worth of coarse-scale nodes. The coarsened structural and data matrices for the next layer are then calculated as: Clearly, the additional GCN layers required to produce incur additional computational cost. We compare our 3-level GPCN (adaptive and not) models from the experiment in Section 7.5.5 to a model which has the same structure, but in which each matrix is replaced by the appropriately-sized output of a DiffPool module, and furthermore the coarsened structure matrices are produced as in Equation [eqn:diffpool_rule].
We see that our GPCN model achieves comparable validation loss with less computational work, and our A-GPCN model additionally achieves lower absolute validation loss.
Comparison to Other GCN Ensemble Models
[tab:ensemble_models]
c
| Structure Matrix | GCN Filters | Dense Filters |
Single GCN
| 64,64,64 | 256, 32, 8, 1 |
2-GCN Ensemble
| 64,64,64 | 256, 32, 8, 1 | |
| 32,32,32 | 256, 32, 8, 1 |
3-GCN Ensemble
| 64,64,64 | 256, 32, 8, 1 | |
| 32,32,32 | 256, 32, 8, 1 | |
| 16,16,16 | 256, 32, 8, 1 |
2-level GPCN
| 64,64,64 | 256, 32, 8, 1 | |
| 32,32,32 | 256, 32, 8, 1 |
3-level GPCN
| 64,64,64 | 256, 32, 8, 1 | |
| 32,32,32 | 256, 32, 8, 1 | |
| 16,16,16 | 256, 32, 8, 1 |
N-GCN (radii 1,2,4)
| 64,64,64 | 256, 32, 8, 1 |
N-GCN (radii 1,2,4,8,16)
| 64,64,64 | 256, 32, 8, 1 |
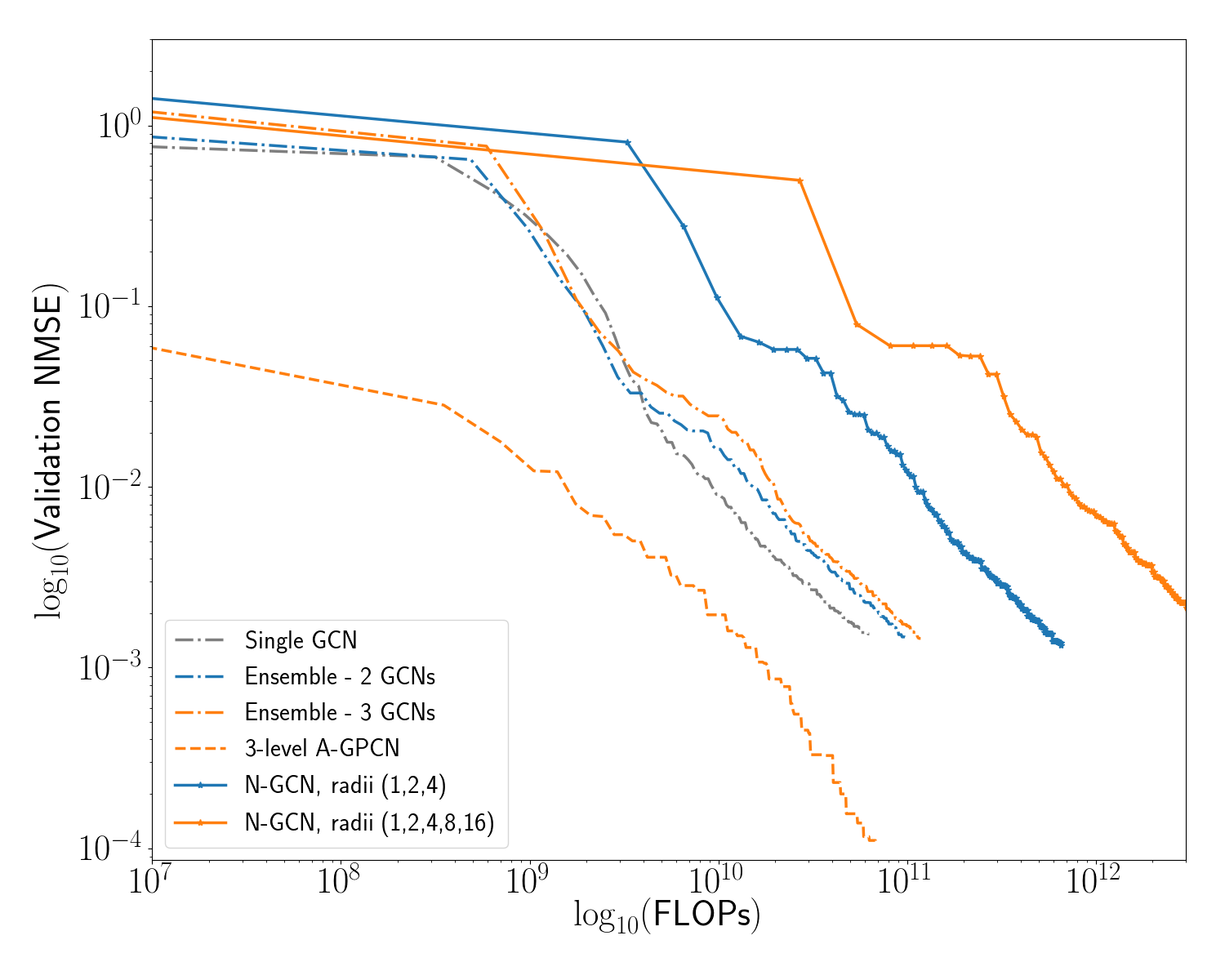
[fig:gcn_comp]
0.15in
| Model Name | Mean NMSE Std. Dev () | Min NMSE () |
|---|---|---|
| Single GCN | 1.55 0.10 | 1.45914 |
| Ensemble - 2 GCNs | 1.44 0.07 | 1.38313 |
| Ensemble - 3 GCNs | 1.71 0.20 | 1.43059 |
| 2-level GPCN | 1.43 0.12 | 1.24838 |
| 2-level A-GPCN | 0.17 0.05 | 0.08963 |
| 3-level GPCN | 2.09 0.32 | 1.57199 |
| 3-level A-GPCN | 0.131 0.030 | 0.10148 |
| N-GCN | 1.30 0.05 | 1.23875 |
| N-GCN | 1.30 0.06 | 1.22023 |
| DiffPool | 2.041 n/a | 2.041 |
[tab:err_comparison]
0.15in
| Model Name | Mean time per batch (s) |
|---|---|
| Single GCN | 0.042 |
| Ensemble - 2 GCNs | 0.047 |
| Ensemble - 3 GCNs | 0.056 |
| 2-level GPCN | 0.056 |
| 2-level A-GPCN | 0.056 |
| 3-level GPCN | 0.061 |
| 3-level A-GPCN | 0.059 |
| N-GCN, radii (1,2,4) | 0.067 |
| N-GCN, radii (1,2,4,8,16) | 0.086 |
| DiffPool | 0.0934 |
[tab:wallclock]
In this experiment we demonstrate the efficiency advantages of our model by comparing our approach to other ensemble Graph Convolutional Networks. Within each ensemble, ours and others, each GCN model consists of several graph convolution layers, followed by several dense layers which are applied to each node separately (node-wise dense layers can be alternatively understood as a GCN layer with , although we implement it differently for efficiency reasons). The input to the dense layers is the node-wise concatenation of the output of each GCN layer. Each ensemble is the sum output of several such GCNs. We compare our models to 1, 2, and 3- member GCN ensembles with the same number of filters (but all using the original fine-scale structure matrix).
We also compare our model to the work of Abu-El-Haija et. al (Abu-El-Haija et al. 2018), who introduce the N-GCN model: an ensemble GCN in which each ensemble member uses a different power of the structure matrix (to aggregate information from neighborhoods of radius ). We include a N-GCN with radii (1,2,4) and a N-GCN with radii (1,2,4,8,16).
We summarize the structure of each of our models in Table [tab:ensemble_models]. In Figure [fig:gcn_comp] we show a comparison between each of these models, for one particular random seed (42). Error on the validation set is tracked as a function of computational cost expended to train the model (under our cost assumption given above). We see that all four GPCN models outperform the other types of ensemble model during early training, in the sense that they reach lower levels of error for the same amount of computational work performed. Additionally, the adaptive GPCN models outperform all other models in terms of absolute error: after the same number of training epochs (using the same random seed) they reach an order of magnitude lower error. Table [tab:err_comparison] shows summary statistics for several runs of this experiment with varying random seeds; we see that the A-GPCN models consistently outperform all other models considered. Note that Figures [fig:gcn_comp],[fig:diff_comp], and [fig:gpcn_schedule] plot the Normalize Mean Squared Error (NMSE). This unitless value compares the output signal to the target after both are normalized by the procedure described in section 7.4.1.
Machine Learning Summary
The machine learning model presented in Section 7.3.4 is validated through numerical experiments on an evaluation dataset. First, variations of our architecture are compared in Section 7.5.2, demonstrating that deeper versions of this architecture perform significantly better, and that re-training the matrices leads to further accuracy gains. In Section 7.5.3, we fix the model architecture to be the best-performing of those considered in Section 7.5.2, and examine the effect of varying training schedules, including multigrid-like and coarse-to-fine training. These experiments demonstrate that our model achieves comparable error in less computation when trained in a multigrid fashion. Finally in Sections 7.5.4 and 7.5.5, we validate our model by training other types of graph convolutional network models on the same learning task. We show significant accuracy gains over previous GCN ensemble models such as (Abu-El-Haija et al. 2018) and also outperform DiffPool (Ying et al. 2018), which learns pooling maps during the training process. All results comparing our model to other GCN models are summarized in Tables [tab:err_comparison] and [tab:wallclock]. Together these experiments demonstrate the superior accuracy and efficiency of our machine learning architecture.
Future Work
Differentiable Models of Molecular Dynamics
This work demonstrates the use of feed-forward neural networks to approximate the energetic potentials of a mechanochemical model of an organic molecule. Per-timestep, GCN models may not be as fast as highly-parallelized, optimized MD codes. However, neural networks are highly flexible function approximators: the GCN training approach outlined in this paper could also be used to train a GCN which predicts the energy levels per particle at the end of a simulation (once equilibrium is reached), given the boundary conditions and initial conditions of each particle. In the case of our MT experiments, approximately steps were required to reach equilibrium. The computational work to generate a suitably large and diverse training set would then be amortized by the GCN’s ability to generalize to initial conditions, boundary conditions, and hyperparameters outside of this data set. Furthermore, this GCN reduced model would be fully differentiable, making it possible to perform gradient descent with respect to any of these inputs. In particular, we derive here the gradient of the input to a GCN model with respect to its inputs.
Derivation of Energy Gradient w.r.t Position
As described above, the output of our GCN (or GPCN) model is a matrix (or vector) , representing the energy of each simulated particle.. The total energy of the molecule at position is given by a sum over monomers, . Note that any GCN’s initial layer update is given by the update rule: $$\begin{aligned} X^` &= g_1\left(Z X W_1 +b_1 \right). \end{aligned}$$ During backpropagation, as an intermediate step of computing the partial derivatives of energy with respect to and , we must compute the partial of energy with respect to the input to the activation function : $$\begin{aligned} A_1 &= Z X W_1 +b_1 \\ X^` &= g_1(A_1). \\ \end{aligned}$$ We therefore assume we have this derivative. By the Chain Rule for matrix derivatives: $$\begin{aligned} {\left[\frac{\partial E}{\partial X} \right]}_{ij} = \frac{\partial E}{\partial {\left[ X \right]}_{ij} } &= \sum_{k,p} \frac{\partial E}{\partial {\left[ A_1 \right]}_{kp}} \frac{\partial {\left[ A_1 \right]}_{kp}}{\partial [x_{ij}]}. \nonumber \intertext{Since} {\left[ A_1 \right]}_{kp} &= \left( \sum_{c,d} {\left[ Z \right]}_{kc}{\left[ X \right]}_{cd}{\left[ W_1 \right]}_{dp} \right) + {\left[ b_1 \right]}_{kp} \nonumber \intertext{ and therefore } \frac{\partial {\left[ A_1 \right]}_{kp}}{\partial {\left[ X \right]}_{ij}} &= {\left[ Z \right]}_{ki}{\left[ W_1 \right]}_{jp}, \nonumber \\ \frac{\partial E}{\partial {\left[ X \right]}_{ij}} &= \sum_{k,p} \frac{\partial E}{\partial {\left[ A_1 \right]}_{kp}} {\left[ Z \right]}_{ki} {\left[ W_1 \right]}_{jp} \nonumber \\ \frac{\partial E}{\partial X} &= Z^T \frac{\partial E}{\partial A_1} W_1^T. \label{eqn:gnn_backprop_rule} \end{aligned}$$
Furthermore, since our GPCN model is a sum of the output of several GCNs, we can also derive a backpropagation equation for the gradient of the fine-scale input, , with respect to the energy prediction of the entire ensemble. Let represent the total4 fine-scale energy prediction of the th member of the ensemble, so that . Then, let be the application of Equation [eqn:gnn_backprop_rule] to each GCN in the ensemble. Since the input to the th member of the ensemble is given by , we can calculate the gradient of with respect to , again using the Chain Rule:
$$\begin{aligned} \frac{\partial E^{(i)}}{\partial {\left[ \mathbf{X} \right]}_{mn} } &= \sum_{s=1}^{N_s} \sum_{t=1}^{N_t} \frac{\partial E^{(i)}}{\partial {\left[ X^{(i)} \right]}_{st} } \frac{\partial {\left[ X^{(i)} \right]}_{st} }{\partial {\left[ \mathbf{X} \right]}_{mn}} \nonumber \\ &= \sum_{s=1}^{N_s} \sum_{t=1}^{N_t} \frac{\partial E^{(i)}}{\partial {\left[ X^{(i)} \right]}_{st}} \frac{\partial \left[ P_{1,i}^T \mathbf{X} \right]_{st}}{\partial {\left[ \mathbf{X} \right]}_{mn}} \nonumber \\ &= \sum_{s=1}^{N_s} \sum_{t=1}^{N_t} \frac{\partial E^{(i)}}{\partial {\left[ X^{(i)} \right]}_{st}} \delta_{tm} {\left[ P_{1,i} \right]}_{ns} \nonumber \\ &= \sum_{s=1}^{N_s} \frac{\partial E^{(i)}}{\partial {\left[ X^{(i)} \right]}_{sm}} {\left[ P_{1,i} \right]}_{ns} \nonumber \\ \intertext{Therefore,} \frac{\partial E^{(i)}}{\partial {\left[ \mathbf{X} \right]}_{mn}} &= P_{1,i} \frac{\partial E^{(i)}}{\partial X^{(i)}} \nonumber \intertext{and so} \frac{\partial E}{\partial \mathbf{X}} &= \sum_{i=1}^k \frac{\partial E^{(i)}}{\partial \mathbf{X}} = \sum_{i=1}^k P_{1,i} \frac{\partial E^{(i)}}{\partial X^{(i)}} \nonumber\end{aligned}$$
&=
&=
&=
This backpropagation rule may then be used to adjust , and thereby find low-energy configurations of the molecular graph. Additionally, analogous to the GCN training procedure outlined in Section 7.5.3, this optimization over molecule positions could start at the coarse scale and be gradually refined.
Tensor Factorization
Recent work has re-examined GCNs in the context of the extensive literature on tensor decompositions. LanczosNet (Liao et al. 2019), uses QR decomposition of the structure matrix to aggregate information from large neighborhoods of the graph. The “Tensor Graph Convolutional Network" of Zhang et. al (Zhang et al. 2018), is a different decomposition method, based on graph factorization; a product of GCNs operating on each factor graph can be as accurate as a single GCN acting on the product graph. Since Theorem [theorem:spectralzero] shows that the GDD of a graph product is bounded by the distances between the factor graphs, it seems reasonable to combine both ideas into a model which uses a separate GPCN for each factor. One major benefit of this approach would be that a transfer-learning style approach can be used. For example, we could train a product of two GCN models on a short section of microtubule; and then re-use the weights in a model that predicts energetic potentials for a longer microtubule. This would allow us to extend our approach to MT models whose lengths are biologically relevant, e.g. tubulin monomers.
Graph Limits
Given that in vivo microtubules are longer than the one simulated in this paper by a factor of as much as 200x, future work will focus on scaling these methods to the limit of very large graphs. In particular, this means repeating the experiments of Sections 7.5, but with longer tube graphs. We hypothesise that tube graphs which are closer to the microtubule graph (under the LGDD) as their length will be more efficient reduced-order models for a GPCN hierarchy. This idea is similar to the “graphons” (which are the limits of sequences of graphs which are Cauchy under the Cut-Distance of graphs) introduced by Lovász (Lovász 2012). To show that it is reasonable to define a “graph limit” of microtubule graphs in this way, we plot the distance between successively longer microtubule graphs. Using the same notation as in Section 7.4.3, we define three families of graphs:
: Grids of dimensions , and;
: Microtubule graphs with protofilaments, of length , with offset 1, and;
: Microtubule graphs with protofilaments, of length , with offset 3.
In this preliminary example, as is increased, we see a clear distinction in the distances and , with the former clearly limiting to a larger value as .
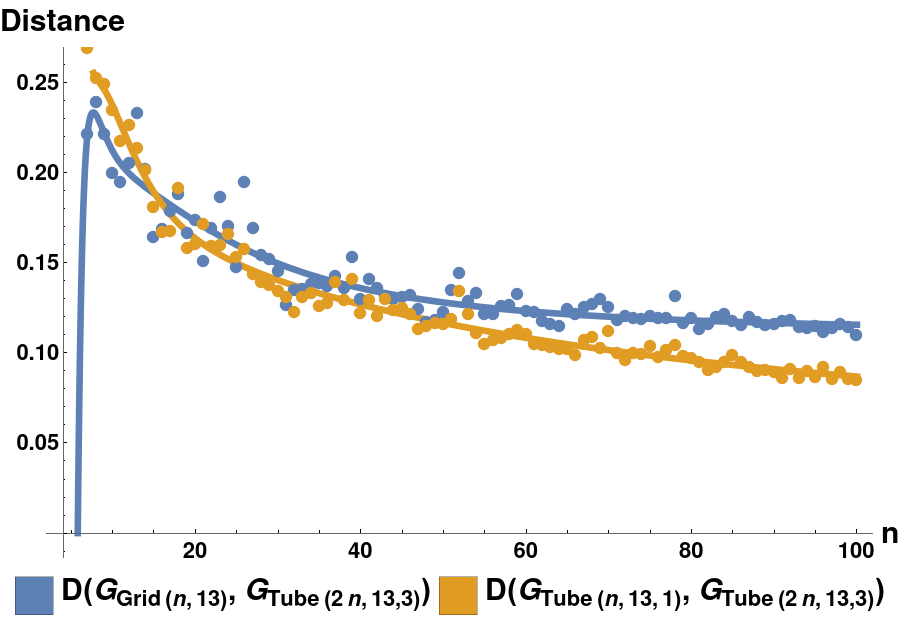
[fig:limit_test]
Conclusion
We introduce a new type of graph ensemble model which explicitly learns to approximate behavior at multiple levels of coarsening. Our model outperforms several other types of GCN, including both other ensemble models and a model which coarsens the original graph using DiffPool. We also explore the effect of various training schedules, discovering that A-GPCNs can be effectively trained using a coarse-to-fine training schedule. We present the first use of GCNs to approximate energetic potentials in a model of a microtubule.