Numerical Properties of GDD
Previous chapters have introduced graph diffusion distance and explored some of its theoretical properties, as well as demonstrating an efficient method for computing GDD. This chapter presents several experiments, using the machinery developed in Chapter 4 to explore numerical properties of GDD as well as numerical properties of Algorithm [alg:linear_alg].
Graph Lineages
In this section we introduce several specific graph lineages for which we will compute various intra- and inter-lineage distances. Three of these are well-known lineages of graphs, and the fourth is defined in terms of a product of complete graphs:
Path Graphs (): 1D grid graphs of length , with aperiodic boundary conditions.
Cycle Graphs (): 1D grid graphs of length , with periodic boundary conditions.
Square Grid Graphs (): 2D grid graphs of dimensions , with aperiodic boundary conditions.
“Multi-Barbell” Graphs (): Constructed as , where is the complete graph on vertices.
These familes are all illustrated in Figure [fig:graph_families].
2D Grids

Paths

Cycles

k-Barbell graphs

[fig:graph_families]
Additionally, some examples distances between elements of these graph lineages are illustrated in Figure [fig:gdist_plots]. In these tables we see that in general intra-lineage distances are small, and inter-lineage distances are large.


[fig:gdist_plots]
Numerical Optimization Methods
We briefly discuss here the other numerical methods we have used to calculate and . In general we have found these methods inferior to the algoithm presented in Chapter 4, but we present them here for completeness.
Nelder-Mead in Mathematica For very small graph pairs () we are able to find optimal using constrained optimization in Mathematica 11.3 (Inc., n.d.) using NMinimize, which uses Nelder-Mead as its backend by default. The size limitation made this approach unusable for any real experiments.
Orthogonally Constrained Opt. We also tried a variety of codes specialized for numeric optimization subject to orthogonality constraints. These included (1) the python package PyManopt (Townsend, Koep, and Weichwald 2016), a code designed for manifold-constrained optimization; (2) gradient descent in Tensorflow using the penalty function (with a small positive constant weight) to maintain orthogonality, as well as (3) an implementation of the Cayley reparametrization method from (Wen and Yin 2013) (written by the authors of that same paper). In our experience, these codes were slower, with poorer scaling with problem size, than combinatorial optimization over subpermutation matrices, and did not produce improved results on our optimization problem.
Black-Box Optimization Over .
We compare in more detail two methods of joint optimization over and when is constrained to be a subpermutation matrix in the diagonal basis for and . Specifically, we compare our approach given in Algorithm [alg:linear_alg] to univariate optimization over , where each function evaluation consists of full optimization over . Figure [fig:alg_timing] shows the results of this experiment. We randomly sample pairs of graphs as follows:
is drawn uniformly from .
is drawn uniformly from .
and are generated by adding edges according to a Bernoulli distribution with probability . We ran 60 trials for each in { .125, .25, .375, .5, .625, .75, .875 }.
We compute the linear version of distance for each pair. Because our algorithm finds all of the local minima as a function of alpha, we compute the cost of the golden section approach as the summed cost of multiple golden section searches in alpha: one GS search starting from the initial bracket for each local minimum found by our algorithm. We see that our algorithm is always faster by at least a factor of 10, and occasionally faster by as much as a factor of . This can be attributed to the fact that the golden section search is unaware of the structure of the linear assignment problem: it must solve a full linear assignment problem for each value of it explores. In contrast, our algorithm is able to use information from prior calls to the LAP solver, and therefore solves a series of LAP problems whose sizes are monotonically nonincreasing.
![Comparison of runtimes for our algorithm and bounded golden section search over the same interval [ 10^{-6}, 10]. Runtimes were measured by a weighted count of evaluations of the Linear Assignment Problem solver, with an n \times n linear assignment problem counted as n^3 units of cost. Because our algorithm recovers the entire lower convex hull of the objective function as a function of \alpha, we compute the cost of the golden section search as the summed cost of multiple searches, starting from an interval bracketing each local optimum found by our algorithm. We see that our algorithm is much less computationally expensive, sometimes by a factor of 10^{3}. The most dramatic speedup occurs in the regime where n_1 << n_2. Graphs were generated by drawing n_1 uniformly from [5,120], drawing n_2 uniformly from [n_1, n_1 + 60], and then adding edges according to a Bernoulli distribution with p in { .125, .25, .375, .5, .625, .75, .875 } (60 trials each).](../media/file12.png)
[fig:alg_timing]
Triangle Inequality violation of (Exponential Distance) and (Linear Distance)
As stated in Section 2.3, our full graph dissimilarity measure does not necessarily obey the triangle inequality. In this section we systematically explore conditions under which the triangle inequality is satisfied or not satisfied. We generate triplets of random graphs of sizes for , , and by drawing edges from the Bernoulli distribution with probability (we perform 4500 trials for each value in [.125, .25, .375, .5, .625, .75, .875]). We compute the distance (for ). The results may be seen in Figure [fig:triangle_ineq_histogram]. In this figure we plot a histogram of the “discrepancy score” which measures the degree to which a triplet of graphs violates the triangle inequality (i.e. falls outside of the unit interval [0,1]), for approximately such triplets. It is clear that, especially for the linear definition of the distance, the triangle inequality is not always satisfied. However, we also observe that (for graphs of these sizes) the discrepancy score is bounded: no triple violates the triangle inequality by more than a factor of approximately 1.8. This is shown by the histogram of discrepancies in Figure [fig:triangle_ineq_histogram]. Additionally, the triangle inequality is satisfied in 28184 (95.2%) of cases.
We see similar but even stronger results when we run the same experiment with instead of ; these may also be seen in Figure [fig:triangle_ineq_histogram]. We calculated the discrepancy score analogously, but with substituted for . We see similarly that the degree of violation is bounded. In this case, no triple violated the triangle inequality by a factor of more than 5, and in this case the triangle inequality was satisfied in 99.8% of the triples. More work is needed to examine this trend; in particular, it would be interesting to examine whether other models of graph generation also satisfy the triangle inequality up to this constant. In both of these cases, the triangle inequality violations may be a result of our optimization procedure finding local minima/maxima for one or more of the three distances computed. We also repeat the above procedure for the same triplets of graphs, but with distances computed not in order of increasing vertex size: calculating and . All of these results are plotted in Figure [fig:triangle_ineq_histogram].
![Histograms of triangle inequality violation. These plots show the distribution of \text{Disc}(G_1, G_2, G_3), as defined in the text, for the cases (a) top: the linear or small-time version of distance and (b) bottom: the exponential or arbitrary-time version of distance. We see that for the sizes of graph we consider, the largest violation of the triangle inequality is bounded, suggesting that our distance measure may be an infra-\rho-pseudometric for some value of \rho \approx 1.8 (linear version) or \rho \approx 5.0 (exponential version). See Table [tab:dist_versions] for a summary of the distance metric variants introduced in this paper. We also plot the same histogram for out-of-order (by vertex size) graph sequences: \text{Disc}(G_2, G_1, G_3) and \text{Disc}(G_3, G_2, G_1). Each plot has a line at x=1, the maximum discrepancy score for which the underlying distances satisfy the triangle inequality.](../media/file13.png "fig:")
![Histograms of triangle inequality violation. These plots show the distribution of \text{Disc}(G_1, G_2, G_3), as defined in the text, for the cases (a) top: the linear or small-time version of distance and (b) bottom: the exponential or arbitrary-time version of distance. We see that for the sizes of graph we consider, the largest violation of the triangle inequality is bounded, suggesting that our distance measure may be an infra-\rho-pseudometric for some value of \rho \approx 1.8 (linear version) or \rho \approx 5.0 (exponential version). See Table [tab:dist_versions] for a summary of the distance metric variants introduced in this paper. We also plot the same histogram for out-of-order (by vertex size) graph sequences: \text{Disc}(G_2, G_1, G_3) and \text{Disc}(G_3, G_2, G_1). Each plot has a line at x=1, the maximum discrepancy score for which the underlying distances satisfy the triangle inequality.](../media/file14.png "fig:")
![Histograms of triangle inequality violation. These plots show the distribution of \text{Disc}(G_1, G_2, G_3), as defined in the text, for the cases (a) top: the linear or small-time version of distance and (b) bottom: the exponential or arbitrary-time version of distance. We see that for the sizes of graph we consider, the largest violation of the triangle inequality is bounded, suggesting that our distance measure may be an infra-\rho-pseudometric for some value of \rho \approx 1.8 (linear version) or \rho \approx 5.0 (exponential version). See Table [tab:dist_versions] for a summary of the distance metric variants introduced in this paper. We also plot the same histogram for out-of-order (by vertex size) graph sequences: \text{Disc}(G_2, G_1, G_3) and \text{Disc}(G_3, G_2, G_1). Each plot has a line at x=1, the maximum discrepancy score for which the underlying distances satisfy the triangle inequality.](../media/file15.png "fig:")
[fig:triangle_ineq_histogram]
Intra- and Inter-Lineage Distances
We compute pairwise distances for sequences of graphs in the graph lineages displayed in Figure [fig:graph_families]. For each pair of graph families (Square Grids, Paths, Cycles, and Multi-Barbells), we compute the distance from the th member of one lineage to the -st member of each other lineage, and take the average of the resulting distances from to . These distances are listed in Table [tab:dist_table]. As expected, average distances within a lineage are smaller than the distances from one lineage to another.
| Square Grids | Paths | Cycles | Multi-Barbells | |
|---|---|---|---|---|
| Square Grids | 0.0096700 | 0.048162 | 0.046841 | 0.63429 |
| Paths | 0.30256 | 0.0018735 | 0.010300 | 2.1483 |
| Cycles | 0.27150 | 0.0083606 | 0.0060738 | 2.0357 |
| Multi-Barbells | 0.21666 | 0.75212 | 0.72697 | 0.029317 |
[tab:dist_table]
We note here that the idea of computing intra- and inter- lineage distances is similar to recent work (Hartle et al. 2020) computing distances between graph ensembles: certain classes of similarly-generated random graphs. Graph diffusion distance has been previously shown (in (Hartle et al. 2020)) to capture key structural information about graphs; for example, GDD is known to be sensitive to certain critical transitions in ensembles of random graphs as the random parameters are varied. This is also true for our time dilated version of GDD. More formally: let and represent random graphs on vertices, drawn from the Erdős-Renyi distribution with edge probability . Then has a local maximum at , representing the transition between disconnected and connected graphs. This is true for our distance as well as the original version due to Hammond.
Graph Limits
Here, we provide preliminary evidence that graph distance measures of this type may be used in the definition of a graph limit - a graphlike object which is the limit of an infinite sequence of graphs. This idea has been previously explored, most famously by Lovász (Lovász 2012), whose definition of a graph limit (called a graphon) is as follows: Recall the definition of graph cut-distance from Equation [defn:cut_dist], namely: the cut distance is the maximum discrepancy in sizes of edge-cuts, taken over all possible subsets of vertices, between two graphs on the same vertex-set. A graphon is then an equivalence class of Cauchy sequences of graphs1, under the equivalence relation that two sequences and are equivalent if approaches 0 as .
We propose a similar definition of graph limits, but with our diffusion distance substituted as the distance measure used in the definition of a Cauchy sequence of graphs. Hammond et. al. argue in (Hammond, Gur, and Johnson 2013) why their variant of diffusion distance may be a more descriptive distance measure than cut-distance. More specifically, they show that on some classes of graphs, some edge deletions ‘matter’ much more than others: removal of a single edge changes the diffusive properties of the graph significantly. However, the graph-cut distance between the new and old graphs is the same, regardless of which edge has been removed, while the diffusion distance captures this nuance. For graph limits, however, our generalization to unequal-sized graphs via is of course essential. Furthermore, previous work (Borgs et al. 2019) on sparse graph limits has shown that in the framework of Lovász all sequences of sparse graphs converge (in the infinite-size limit) to the zero graphon. Graph convergence results specific to sparse graphs include the Benjamini-Schramm framework (Benjamini and Schramm 2001), in which graph sequences are compared using the distributional limits of subgraph frequencies. These two graph comparison methods both have the characteristic that the “limit object” of a sequence of graphs is rigorously defined. It is unclear that density functions on the unit square are the best choice of limit objects for graphs; while graphons have many nice properties as detailed by Lovász, other underlying limit objects may be a more natural choice for sparse graphs. In this section we attempt to show empirically that such a limit object of graph sequences under GDD may exist, and therefore merit further investigation.
We examine several sequences of graphs of increasing size for the required Cauchy behavior (in terms of our distance measure) to justify this variant definition of a “graph limit”. For each of the graph sequences defined in Section 5.1, we examine the distance between successive members of the sequence, plotting for each choice of and . These sequences of distances are plotted in Figure [fig:g_limits].
In this figure, we see that generally distance diverges between different graph lineages, and converges for successive members of the same lineage, as . We note the exceptions to this trend:
The distances between -paths and -cycles appear to be converging; this is intuitive, as we would expect that difference between the two spectra due to distortion from the ends of the path graph would decrease in effect as .
We also show analytically, under similar assumtions, that the distance between successive path graphs also shrinks to zero (Theorem [thm:pa_lim_lem]).
We do not show that all similarly-constructed graph sequences display this Cauchy-like behavior. We hope to address this deeper question, as well as a more formal exploration of the limit object, with one or more modified versions of the objective function (see Section 3.8.1).
Limit of Path Graph Distances
In this section, we demonstrate analytically that the sequence of path graphs of increasing size is Cauchy in the sense described by the previous section. In the following theorem (Theorem [thm:pa_lim_lem]), we assume that the optimal value of approaches some value as . We have not proven this to be the case, but have observed this behavior for both square grids and path graphs (see Figure [fig:path_lim] for an example of this behavior). Lemmas [lem:path_eigen_limit] and [thm:pa_lim_lem] show a related result for path graphs; we note that the spectrum of the Laplacian (as we define it in this paper) of a path graph of size is given by
[lem:path_eigen_limit] For any finite , we have
Clearly for finite Then, Evaluating this expression requires applying L’Hôpital’s rule. Hence, we have: Since both of the limits $$\begin{aligned} \lim_{n \rightarrow \infty} \left(\frac{n^2 \sin \left(\frac{\pi k}{n+1}\right) e^{2 t \left(\cos \left(\frac{\pi k}{n+1}\right)-1\right)}}{(n+1)^2} \right) \nonumber \\ \intertext{and} \lim_{n \rightarrow \infty} \left(-\sin \left(\frac{\pi k}{n}\right) e^{2 t \left(\cos \left(\frac{\pi k}{n}\right)-1\right)}\right) \nonumber \end{aligned}$$ exist (and are 0), $$\begin{aligned} & 2 \pi k t \lim_{n \rightarrow \infty} \left(\frac{n^2 \sin \left(\frac{\pi k}{n+1}\right) e^{2 t \left(\cos \left(\frac{\pi k}{n+1}\right)-1\right)}}{(n+1)^2}-\sin \left(\frac{\pi k}{n}\right) e^{2 t \left(\cos \left(\frac{\pi k}{n}\right)-1\right)}\right) =0 \nonumber \intertext{and therefore} & \lim_{n \rightarrow \infty} n {\left( e^{t(-2 + 2 \cos(\frac{\pi k}{n}))} - e^{t(-2 + 2 \cos(\frac{\pi k}{n+1}))} \right)}^2 = 0 \nonumber\end{aligned}$$
[thm:pa_lim_lem] If $\lim_{n \rightarrow \infty} \arg \sup_t D^2\left( \left. \text{\emph{Pa}}_n, \text{\emph{Pa}}_{n+1} \right| t \right)$ exists, then:
Assume that . Then, we must have Hence, it remains only to prove that for any finite (which will then include ). First, for any particular subpermutation matrix , note that
Here, and are the matrices which diagonalize and respectively (note also that a diagonalizer of a matrix also diagonalizes ). If at each we select to be the subpermutation , then (using the same argument as in Theorem [thm:LAP_bound]) the objective function simplifies to: By Lemma [lem:path_eigen_limit], for any finite , we have So for any , such that when , for any , But then as required. Thus, the Cauchy condition is satisfied for the lineage of path graphs
![Limiting behavior of D and two parameters as path graph size approaches infinity. All distances were calculated between \text{Path}_{n} and \text{Path}_{n+1}. We plot the value of the objective function, as well as the optimal values of \alpha and t, as n \rightarrow \infty. Optimal \alpha rapidly approach 1 and the optimal distance tends to 0. Additionally, the optimal t value approaches a constant (t \approx .316345), providing experimental validation of the assumption we make in proving Theorem [thm:pa_lim_lem].](../media/file16.png)
[fig:path_lim]
Given a graph lineage which consists of levelwise box products between two lineages, it seems natural to use our upper bound on successive distances between graph box products to prove convergence of the sequence of products. As an example, the lineage consisting of square grids is the levelwise box product of the lineage of path graphs with itself. However, in this we see that this bound may not be very tight. Applying Equation [eqn:graph_product_special_case] from Theorem [thm:sq_grid_lim_lem], we have (for any ): As we can see in Figure [fig:sq_dist_vs_bound], the right side of this inequality seems to be tending to a nonzero value as , whereas the actual distance (calculated by our optimization procedure) appears to be tending to zero.
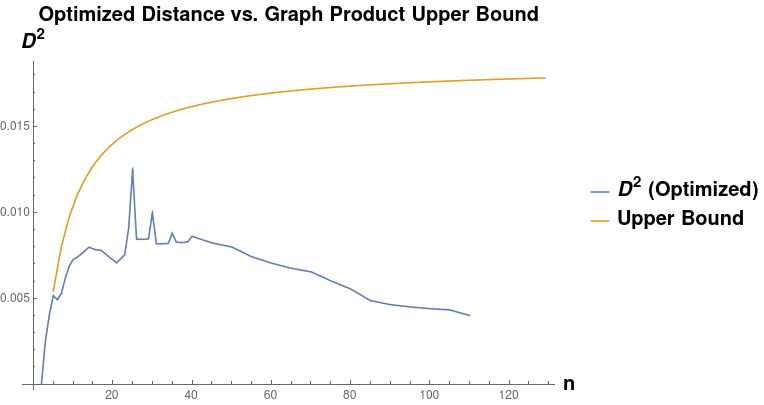
[fig:sq_dist_vs_bound]
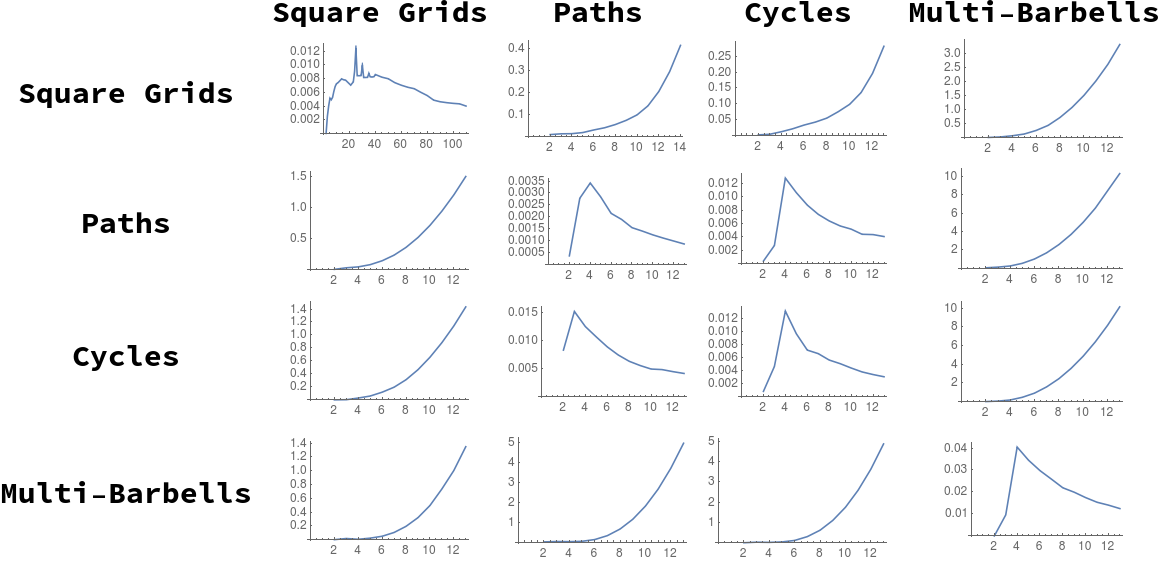
[fig:g_limits]