Diffusion Distance
In this Chapter we provide the definition of Graph Diffusion Distance, as well as providing motivation for why the optimiztion over is an essential component of the GDD calculation. We also briefly introduce some variants of GDD which will be covered in more detail in Chapter 3. The diffusion distance calculations presented throughout this thesis depend on an upper bound of the innermost optimization over and ; in Section 2.4 we define a lower bound on the same optimization. This lower bound will be useful in some of the GDD property proofs in Chapter 3.
Diffusion Distance Definition
We generalize the diffusion distance defined by Hammond et al. (Hammond, Gur, and Johnson 2013). This distortion measure between two undirected graphs and , of the same size, was defined as: where represents the graph Laplacian of . A typical example of this distance, as is varied, can be seen in Figure [fig:hammond_distance].
.](../media/file4.png)
[fig:hammond_distance]
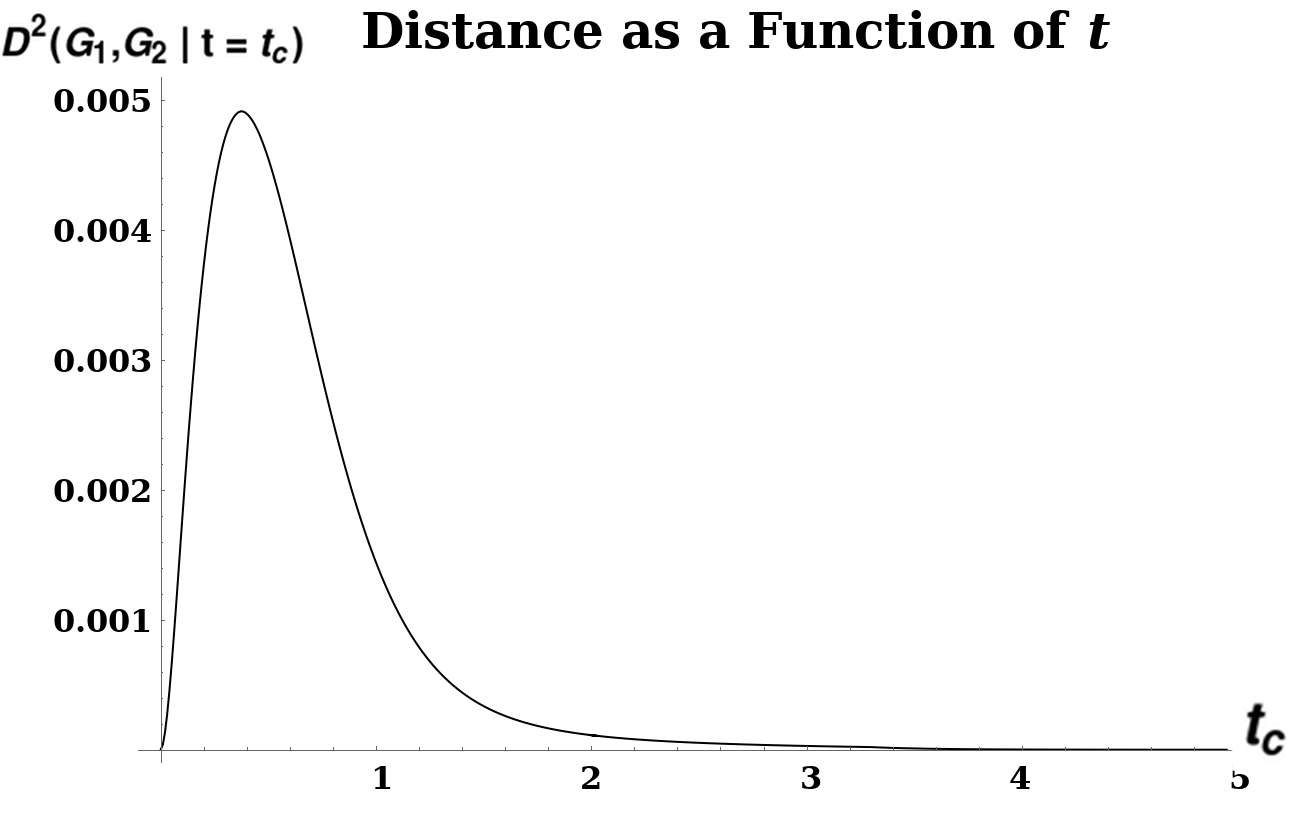
[fig:typical_ham_dist]
This may be interpreted as measuring the maximum divergence, as a function of , between diffusion processes starting from each vertex of each graph, as measured by the squared Euclidean distance between the column vectors of . Each column of (which is called the Laplacian Exponential Kernel) describes a probability distribution of visits (by a random walk of duration , with node transition probabilities given by the columns of ) to the vertices of , starting at vertex . This distance metric is then measuring the difference between the two graphs by comparing these probability distributions; the motivation between taking the supremum over all is that the value of the objective function at the maximum is the most these two distributions can diverge. See Figure [fig:typical_ham_dist] for an example of a distance calculation, with a characteristic peak.
For further intuition about why the peak is the most natural place to take as the distance, rather than some other arbitrary time, note that at very early times and very late times, the probability distribution of vertex visits is agnostic to graph structure: at early times no diffusion has had a chance to take place, while at very late times the distribution of vertex-visits converges to the stationary state1 for each connected component of the graph. Hence we are most interested in a regime of -values in between these extremes, where differences in and are apparent in their differing probability distributions.
Our contribution generalizes this measure to allow for graphs of differing size. We add two variables to this optimization: a prolongation operator, (represented as a rectangular matrix), and a time-scaling factor, . The dissimilarity between two graphs and (with Laplacians ) is then defined as: where represents some set of constraints on the matrix . For the remainder of this work we use to refer to the distance and to refer to the squared distance - this notation is chosen to simplify the exposition of some proofs. It will be convenient for later calculations to introduce and assume the concept of transitive constraints - by which we mean that for any constraint , satisfaction of by and implies satisfaction of by their product (when such a product is defined). Some (non-exclusive) examples of transitive constraints include orthogonality, particular forms of sparsity, and their conjunctions.
The simplest transitive constraint we will consider is that should be orthogonal. Intuitively, an orthogonal represents a norm-preserving map between nodes of and nodes of , so we are measuring how well diffusion on approximates diffusion on , as projected by . Note that since in general is a rectangular matrix it is not necessarily true that . We assume that ; if not, the order of the operands is switched, so that is always at least as tall as it is wide. We also briefly consider a sparsity constraint in Section 3.4 below. Since sparsity is more difficult to treat numerically, our default constraint will be orthogonality alone. Other constraints could include bandedness and other structural constraints. We also note that because is finite-dimensional, the exponential map is continuous and therefore we can swap the order of optimization over and . The optimization procedure outlined in this thesis optimizes these variables in the order presented above (namely: an outermost loop of maximization over , a middle loop of minimization over given , and an innermost loop of minimization over given and ).
The other additional parameter, , controls dilation between the passage of time in the two graphs, to account for different scales. Again, the intuition is that we are interested in the difference between structural properties of the graph (from the point of view of single-particle diffusion) independent of the absolute number of nodes in the graph. As an example, diffusion on an grid is a reasonably accurate approximation of more rapid diffusion on a grid, especially when is very large. In our discussion of variants of this dissimilarity score, we will use the notation to mean restrictions of any of our distortion measure equations where variable is held to a constant value ; In cases where it is clear from context which variable is held to a fixed value , we will write
At very early times the second and higher-order terms of the Taylor Series expansion of the matrix exponential function vanish, and so . This motivates the early-time or “linear” version of this distance, :
(Note that the identity matrices cancel). The outermost optimization (maximization over ) is removed for this version of the distance, as can be factored out:
This means that for the linear version, we only optimize and . For the exponential version of the dissimilarity score, we note briefly that the supremum over of our objective function must exist, since for any : In other words, the infimum over all and is bounded above by any particular choice of values for these variables. Since this upper bound must have a supremum (possibly 0) at some . Then must be finite and therefore so must the objective function.
Directedness of Distance and Constraints
We note that this distance measure, as defined so far, is directed: the operands and serve differing roles in the objective function. This additionally makes the constraint predicate ambiguous: when we state that represents orthogonality, it is not clear whether we are referring to or (only one of which can be true for a non-square matrix ). To remove this ambiguity, we will, for the computations in the rest of this manuscript, define the distance metric to be symmetric: the distance between and with is always . is then always at least as tall as it is wide, so of the two choices of orthogonality constraint we select .
Variants of Distance Measure
Thus far we have avoided referring to this graph dissimilarity function as a “distance metric”. As we shall see later, full optimization of Equations [defn:exp_defn] and [defn:linear_defn] over and is too loose, in the sense that the distances , , and do not necessarily satisfy the triangle inequality. The same is true for . See Section 5.3 for numerical experiments suggesting a particular parameter regime where the triangle inequality is satisfied. We thus define several restricted/augmented versions of both and which are guaranteed to satisfy the triangle inequality. These different versions are summarized in Table [tab:dist_versions]. These variously satisfy some of the conditions necessary for generalized versions of distance metrics, including:
Premetric: a function for which and for all .
Pseudometric: As a premetric, but additionally for all .
-inframetric: As a premetric, but additionally and if and only if , for all .
Additionally, we note here that a distance measure on graphs using Laplacian spectra can at best be a pseudometric, since isospectral, non-isomorphic graphs are well-known to exist (Godsil and McKay 1982)(Van Dam and Haemers 2003). Characterizing the conditions under which two graphs are isospectral but not isomorphic is an open problem in spectral graph theory. However, previous computational work has led to the conjecture that “almost all” graphs are uniquely defined by their spectra (Brouwer and Haemers 2011)(Brouwer and Spence 2009)(Van Dam and Haemers 2009), in the sense that the probability of two graphs of size being isospectral but not isomorphic goes to 0 as . Furthermore, our numerical experiments seem to show empirically that the violation of the triangle inequality is bounded, in the sense that for . This means that even in the least restricted case our similarity measure may be a -infra-pseudometric on graphs (and, since such isospectral, non-isomorphic graphs are relatively rare, it behaves like a inframetric). As we will see in Chapter 3, in some more restricted cases we can prove triangle inequalities, making our measure a pseudometric. In Section 4.1, we discuss an algorithm for computing the optima in Equations ([defn:exp_defn]) and ([defn:linear_defn]). First, we discuss some theoretical properties of this dissimilarity measure.
Spectral Lower Bound
In Theorem [thm:LAP_bound] of Chapter 4 we will derive and make use of an upper bound on the graph distance . This upper bound is calculated by constraining the variable to be not only orthogonal, but also where is the solution (i.e. “matching”, in the terminology of that section) to a Linear Assignment problem with costs given by a function of the eigenvalues of and . In this section we derive a similar lower bound on the distance.
Let and be undirected graphs with Laplacians and , and let be constant. By Equation [eqn:simple_d_tilde], we have
The following upper bound on is achieved by constraining to be not only orthogonal, but related to a constrained matching problem between the two lists of eigenvalues:
$$\label{eqn:upper_bound_2_defn} \begin{array}{ll@{}ll} \tilde{D}^2(G_1,G_2) \leq \inf_{\alpha>0} \inf_{M} & {\left| \left| \frac{1}{\alpha} M \Lambda_1 - \alpha \Lambda_2 M \right| \right|}^2_F &\\ \text{subject to}& \displaystyle\sum\limits_{i=1}^{n_2} m_{ij} \leq 1, &j=1 \ldots n_1\\ & \displaystyle\sum\limits_{j=1}^{n_1} m_{ij} \leq 1, &i=1 \ldots n_2\\ & m_{ij} \geq 0 & i = 1 \ldots n_2, j = 1 \ldots n_1, \\ \end{array}$$ where and are diagonal matrices of the eigenvalues of and respectively. Here we used the explicit map as a change of basis; we then converted the constraints on into equivalent constraints on , and imposed additional constraints so that the resulting optimization (a linear assignment problem) is an upper bound. See the proof of Theorem [thm:LAP_bound] for the details of this derivation. We show in this section that a less constrained assignment problem is a lower bound on . We do this by computing the same mapping and then dropping some of the constraints on (which is equivalent to dropping constraints on , yielding a lower bound). The constraint is the conjunction of constraints on the column vectors of : if is the th column of , then is equivalent to: If we discard the constraints in Equation [eqn:p_const_l2], we are left with the constraint that every column of must have unit norm.
Construct the “spectral lower bound matching” matrix as follows:
For any , this matrix is the solution to a matching problem (less constrained than the original optimization over all ) where each is assigned to the closest , allowing collisions. It clearly satisfies the constraints in Equation [eqn:p_const_l1], but may violate those in Equation [eqn:p_const_l2]. Thus, we have
Various algorithms exist to rapidly find the member of a set of points which is closest to some reference point (for example, KD-Trees (Bentley 1975)). For any , the spectral lower bound can be calculated by an outer loop over alpha and an inner loop which applies one of these methods. We do not consider joint optimization of the lower bound over and in this work.
Summary of Distance Metric Versions
Table [tab:dist_versions] summarizes the variants of our distance metric.
| Classification | Treatment in this manuscript | |||
|---|---|---|---|---|
| Fixed at | Fixed at | Pseudometric | Defined in Equation [defn:alpha_1_linear]. Optimized by one pass of LAP solver. Triangle inequality proven in Theorem [thm:constant_alpha_thm]. | |
| Fixed at | Fixed at | Pseudometric | Defined in Equation [eqn:TSGDD_defn]. Optimized by one pass of LAP solver. Triangle inequality proven in Theorem [thm:tsgdd_triangle]. | |
| Fixed at | Optimized | Premetric | Defined in Equation [defn:linear_defn]. Optimized by Algorithm [alg:linear_alg]. Triangle inequality violations examined experimentally in Section 5.3. | |
| Optimized | Fixed at | Metric | When , this is Hammond et. al’s version of graph distance. | |
| Optimized | Optimized | Premetric | Defined in Equation [defn:exp_defn]. Optimized by Algorithm [alg:exponential_alg]. Graph Product upper bound proven in Theorem [thm:sq_grid_lim_lem]. Triangle inequality violations examined experimentally in Section 5.3. Used to calculate graph distances in Sections 5.4 and 5.5. | |
| Fixed at | Fixed at | Pseudometric | Triangle inequality proven in Theorem [thm:constant_alpha_thm]. | |
| Fixed at | Fixed at | Pseudometric | Triangle inequality proven in Theorem [thm:tsgdd_triangle]. | |
| Optimized | Optimized | Discussed in Section 3.4. |
[tab:dist_versions]