![[Back]](graphics/btn.back.gif)
![[Contents]](graphics/btn.contents.gif)
![[Next]](graphics/btn.next.gif)

Web software is designed around a distributed client-server architecture. A Web client (called a Web browser if it is intended for interactive use) is a program which can send requests for documents to any Web server. A Web server is a program that, upon receipt of a request, sends the document requested (or an error message if appropriate) back to the requesting client. Using a distributed architecture means that a client program may be running on a completely separate machine from that of the server, possibly in another room or even in another country. Because the task of document storage is left to the server and the task of document presentation is left to the client, each program can concentrate on those duties and progress independently of each other.
Because servers usually operate only when documents are requested, they put a minimal amount of workload on the computers they run on.
Here's an example of how the process works:
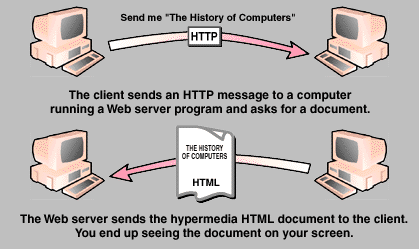
Figure 6. A typical transaction between Web servers and clients.
The World-Wide Web is composed of thousands of these virtual transactions taking place per hour throughout the world, creating a web of information flow.
Future Web servers will include encryption and client authentication abilities - they will be able to send and receive secure data and be more selective as to which clients receive information. This will allow freer communications among Web users and will ensure that sensitive data is kept private. It will be harder to compromise the security of commercial servers and educational servers which wish to keep information local. Improvements in security will facilitate the idea of "pay-per-view" hypermedia, a concept which many commercial interests are pursuing.
The language that Web clients and servers use to communicate with each other is called the Hypertext Transfer Protocol (HTTP). All Web clients and servers must be able to speak HTTP in order to send and receive hypermedia documents. For this reason, Web servers are often called HTTP servers.
The phrase "World-Wide Web" is often used to refer to the collective network of servers speaking HTTP as well as the global body of information available using the protocol.
HTML - The Hypertext Markup Language
The standard language the Web uses for creating and recognizing hypermedia documents is the Hypertext Markup Language (HTML). It is loosely related to, but technically not a subset of, the Standard Generalized Markup Language (SGML), a method of representing document formatting languages. Languages such as HTML which follow the SGML format allow document writers to separate information from document presentation - that is, documents containing the same information can be presented in a number of different ways. Users have the option of controlling visual elements such as fonts, font size and paragraph spacing without changing the original information.
HTML is widely praised for its ease of use. Web documents are typically written in HTML and are usually named with the suffix ".html". HTML documents are nothing more than standard 7-bit ASCII files with formatting codes that contain information about layout (text styles, document titles, paragraphs, lists) and hyperlinks.
Free conversion software is available for translating documents from many other formats into HTML. Filters exist that can convert files in RTF (Rich Text Format), WordPerfect and FrameMaker as well as man pages, mail archives, and text-only documents.
The current HTML standard supports basic hypermedia document creation and layout, but is limited in its capability to support many complex layout techniques found in traditional document publishing. A new version of HTML, called HTML+, is under development and should be completed by the end of 1994. When completed, HTML+ will be backwards compatible with HTML and will support interactive forms, defined "hot spots" in images, more versatile layout and formatting options and styles, and formatted tables.

Figure 7. HTML-formatted documents allow images and hyperlinks to be displayed in documents.
The World-Wide Web uses what are called Uniform Resource Locators (URLs) to represent hypermedia links and links to network services within HTML documents. It is possible to represent nearly any file or service on the Internet with a URL.
The first part of the URL (before the two slashes) specifies the method of access. The second is typically the address of the computer the data or service is located. Further parts may specify the names of files, the port to connect to, or the text to search for in a database. A URL is always a single unbroken line with no spaces.
Sites that run World-Wide Web servers are typically named with a www at the beginning of the network address.
Here are some examples of URLs:
file://www.hcc.hawaii.edu/sound.au -
file://www.eit.com/picture.gif -
file://www.eff.org/directory/ -
http://www.hcc.hawaii.edu/directory/book.html -
ftp://www.xerox.com/pub/file.txt -www.xerox.com and retrieves a text file.
gopher://www.hcc.hawaii.edu -www.hcc.hawaii.edu.
telnet://www.hcc.hawaii.edu:1234 -www.hcc.hawaii.edu at port 1234.
news:alt.hypertext -alt.hypertext newsgroup in hypermedia format.
Most Web browsers allow the user to specify a URL and connect to that document or service. When selecting hypertext in an HTML document, the user is actually sending a request to open a URL. In this way, hyperlinks can be made not only to other texts and media, but also to other network services. Web browsers are not simply Web clients, but are also full-featured FTP, Gopher, and telnet clients.
HTML+ will include an email URL, so hyperlinks can be made to send email automatically. For instance, selecting an email address in a piece of hypertext would open a mail program, ready to send email to that address.