- Goals:
- This assignment is
designed to:
- to teach you how difficult crawling the web is in terms of scale and temporal requirements. The software itself is not the hard part of this assignment, it is managing all the data that comes back. This is only one web site after all.
- to teach you how difficult it is to process text that is not written for computers to consume. Again this is a very structured domain as far as text goes.
- to make the point that web-scale web-centric activities do not lend themselves to "completeness". In some sense you are never done. So thinking about web algorithms in terms of "finishing" doesn't make sense. You have to change your mindset to "best possible" given resources.
- This assignment is
designed to:
- Java Program (100%)
- Administration
- You may work in teams of 1, 2.
- Write a program to crawl the web.
- Inputs
- A URL start Page (the seed set)
- A regular expression
- Pages are only crawled if the url matches this regular expression.
- Output
- A graph of the crawled pages
- An index
- of (term, document) pairs
- A graph of the crawled pages
- Structure
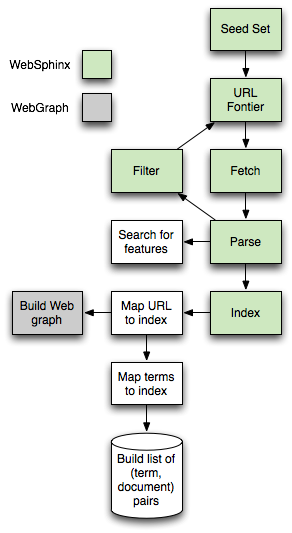
- You can, but don't have to, use two libraries:
- Inputs
-
Using this architecture
search for the following features
- Find the longest Palindrome in wikipedia that is not on a page about palindromes.
- What I want is a palindrome made from English words. Here are some algorithmic guidelines to help you find that:
- First split the page whenever you see a non-ASCII (>127) character. So an arabic character, for example, will never be embedded in a palindrome.
- Second strip all punctuation from the text so that only [A-Za-z0-9] remain.
- Convert all characters to upper or lower case.
- A palindrome consists of the longest common substring between a line of text and its reverse.
- Once you identify all palindromes on a page over X characters, make sure that:
- greater than 5 characters.
- less than 10% of the original text was punctuation.
- What I want is a palindrome made from English words. Here are some algorithmic guidelines to help you find that:
- Find the longest Lipogram (letter "E"/"e") in wikipedia that is not on a page about lipograms.
- What I want is a lipogram made from English words. Here are some algorithmic guidelines to help you find that:
- First split the page whenever you see a non-ASCII (>127) character. So an arabic character, for example, will never be embedded in a lipogram.
- Second strip all punctuation from the text so that only [A-Za-z0-9] remain.
- A lipogram is the longest sequence of text which doesn't contain a particular letter.
- Once you identify all lipograms on a page over X characters, make sure that:
- less than 10% of the original text was punctuation.
- What I want is a lipogram made from English words. Here are some algorithmic guidelines to help you find that:
- Find the Rhopalic with the most number of words in wikipedia.
- What I want is a rhopalic made from English words. Here are some algorithmic guidelines to help you find that:
- First split the page whenever you see a non-ASCII (>127) character. So an arabic character, for example, will never be embedded in a rhopalic.
- For our purposes a rhopalic is a sequence of words in which each word increases by one character.
- The first word has N characters. The second word has N+1 characters. Words are separated by at least 1 and no more than 3 spaces, white space, or punctuation.
- A valid rhopalic then looks like this regular expression:
- \b[A-Za-z]{N}\b[\s!@#$%^&*()-_=+<>,.`~{}\[\]|\\/?]{1,3}\b[A-Za-z]{N+1}\b etc....
- Example: "I am the most happy person talking"
- What I want is a rhopalic made from English words. Here are some algorithmic guidelines to help you find that:
- Find the longest Palindrome in wikipedia that is not on a page about palindromes.
- After crawling the web, use your web graph calculate the shortest path between
- from: http://en.wikipedia.org/wiki/Stonehenge
- to: http://en.wikipedia.org/wiki/Egyptian_pyramids
- that stays in the English content pages of Wikipedia.org
- (100%) Evaluation:
- (60%) Produce the palindrome, lipogram and rhopalic
and source URLs from part 3.
- Grades will be assigned according to the length of the sequence.
- The longest sequence will receive 100%.
- The shortest non-trivial sequence will receive 80%
- Grades will be assigned according to the length of the sequence.
- (30%) Produce your sequence of URLs from part 4.
- Show this sequence as a collection of screen shots indicating the path so that the instructors can verify the path manually.
- Show the anchor text and the URL so that it is easy to verify.
- Grades will be assigned according to the length of the sequence.
- Shortest sequence will receive 100%
- Longest valid sequence will receive 80%. (< 20 hops)
- (10%) Email your results
as a pdf document
- Make the file name
- <LastName1> - < LastName2 > - Assignment02.pdf or
- <LastName1> - Assignment02.pdf
- Make the file name
- (60%) Produce the palindrome, lipogram and rhopalic
and source URLs from part 3.
- Train your group
- Each member of your group must be able to run your architecture on their own for Assignment 03.
- Administration