Automated Generation of Accessibility Test Reports from Recorded User Transcripts
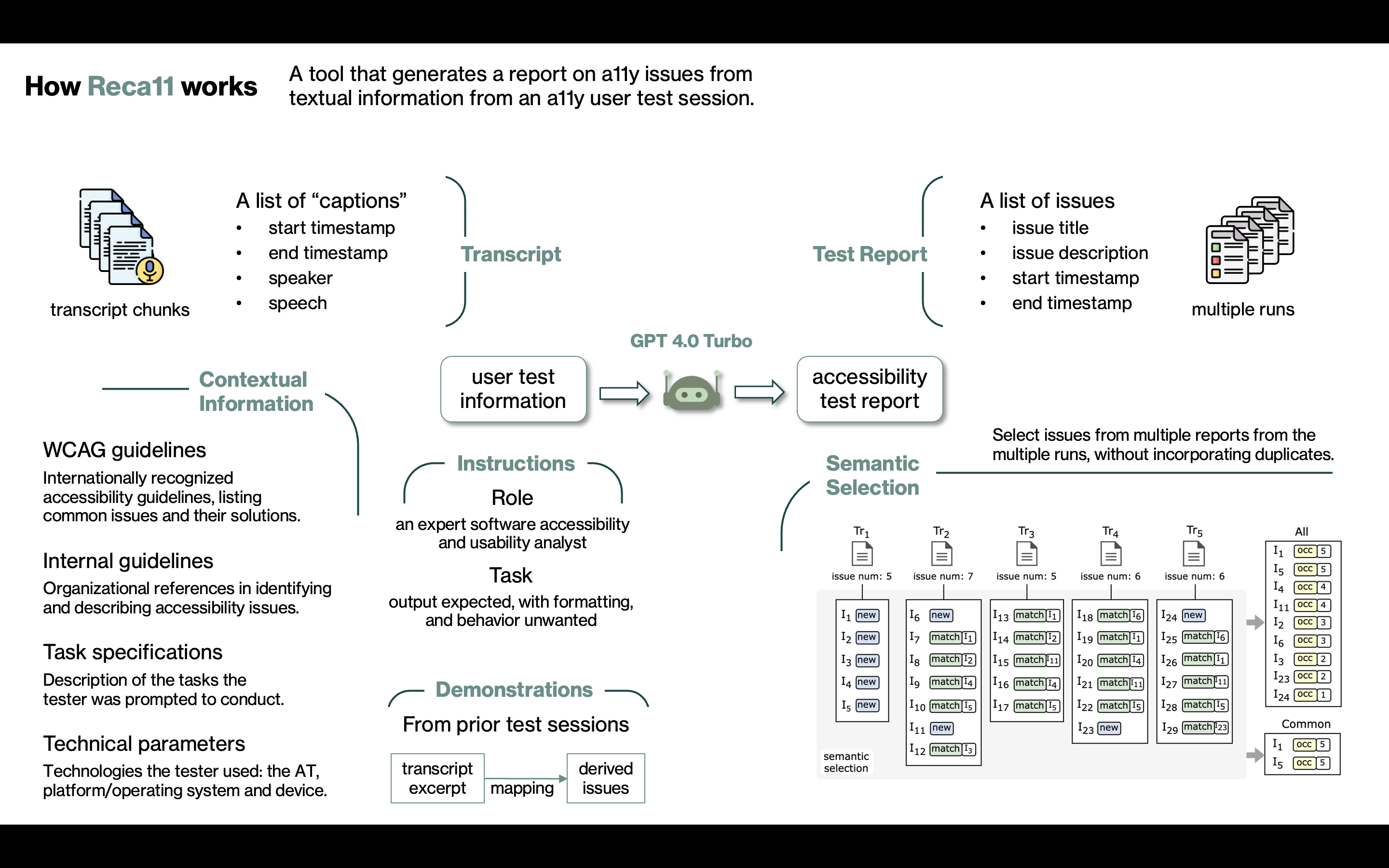
Testing for accessibility is a significant step when developing software, as it ensures that all users, including those with disabilities, can effectively engage with web and mobile applications. While automated tools exist to detect accessibility issues in software, none are as comprehensive and effective as the process of user testing, where testers with various disabilities evaluate the application for accessibility and usability issues. However, user testing is not popular with software developers as it requires conducting lengthy interviews with users and later parsing through large recordings to derive the issues to fix. In this paper, we explore how large language models (LLMs) like GPT 4.0, which have shown promising results in context comprehension and semantic text generation, can mitigate this issue and streamline the user testing process. Our solution, called Reca11, takes in informal transcripts of test recordings and extracts the accessibility and usability issues mentioned by the tester. Our systematic prompt engineering determines the optimal configuration of input, instruction, context and demonstrations for best results. We evaluate Reca11's effectiveness on 36 user testing sessions across three applications. Based on the findings, we investigate the strengths and weaknesses of using LLMs in this space.
Publications
More details about can be found in our publication below:- Automated Generation of Accessibility Test Reports from Recorded User Transcripts
Syed Fatiul Huq, Mahan Tafreshipour, Kate Kalcevich and Sam Malek
47th IEEE/ACM International Conference on Software Engineering (ICSE 2025), Ottawa, Canada, April 2025.
[PDF]
![[seal's logo]](../../seal.png)
![[uci's logo]](../../uci.jpg)